CMU 和 Meta 推出 VQAScore 评估人工智能模型
CMU 和 Meta 推出 VQAScore 评估人工智能模型
生成 AI 技术正在迅速发展,但评估其性能仍然面临持续挑战。随着许多模型展现出令人印象深刻的能力,提出了一个关键问题:应该如何评估 文本到图像模型 的有效性?
传统评估方法通常依赖于 人工视觉检查,这本质上是主观的,或者使用诸如 CLIPScore 的简单指标。这些方法常常无法捕捉到细微文本提示中固有的复杂性,例如对象之间的关系和逻辑推理。结果常常是评估不准确,模型生成的图像可能大大偏离预期,但仍然获得高分。
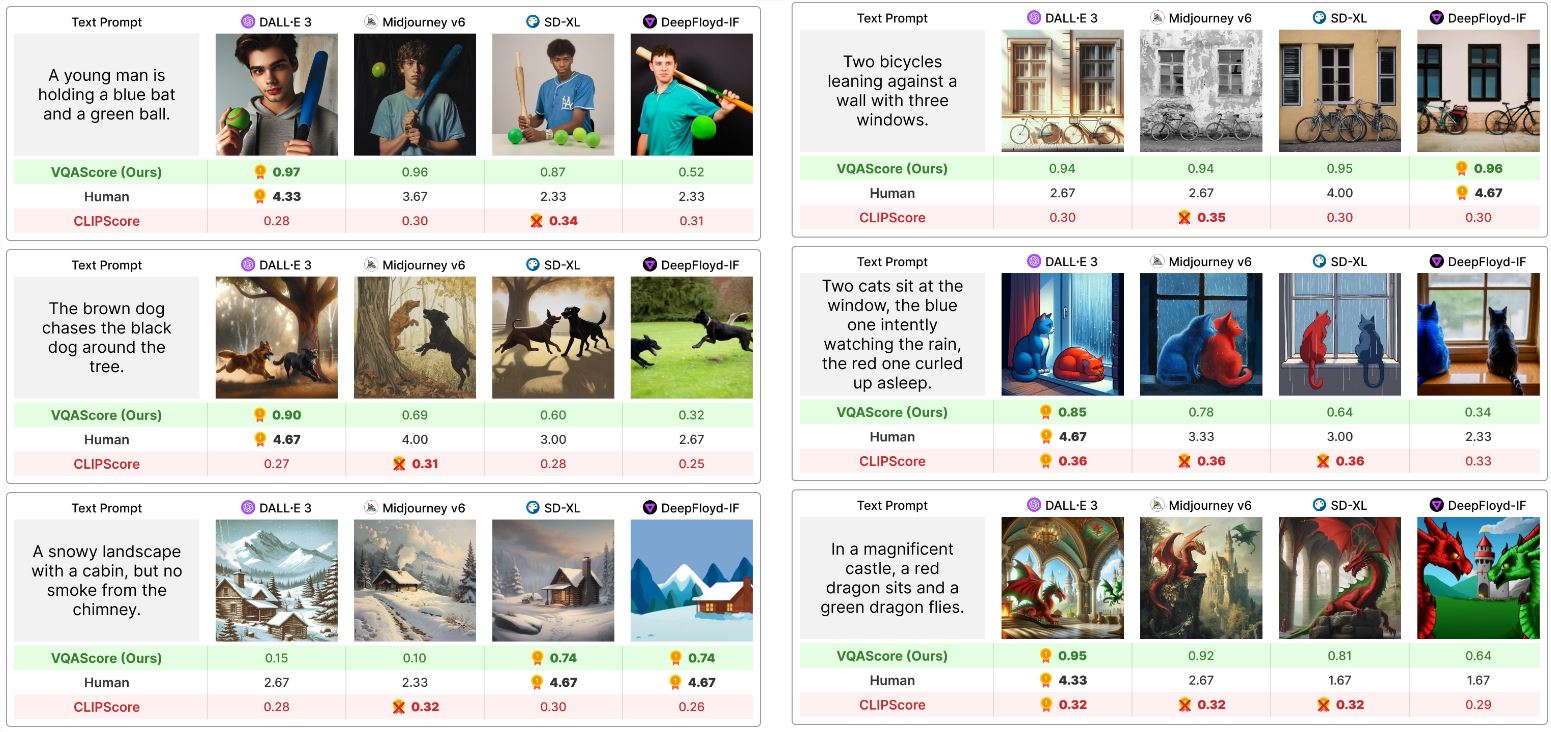
为了解决这个挑战,卡内基梅隆大学 和 Meta 的研究人员合作开发了一种新的评估方案,称为 VQAScore。这一创新的方法利用 视觉问答(VQA) 模型来系统地评估文本到图像模型。
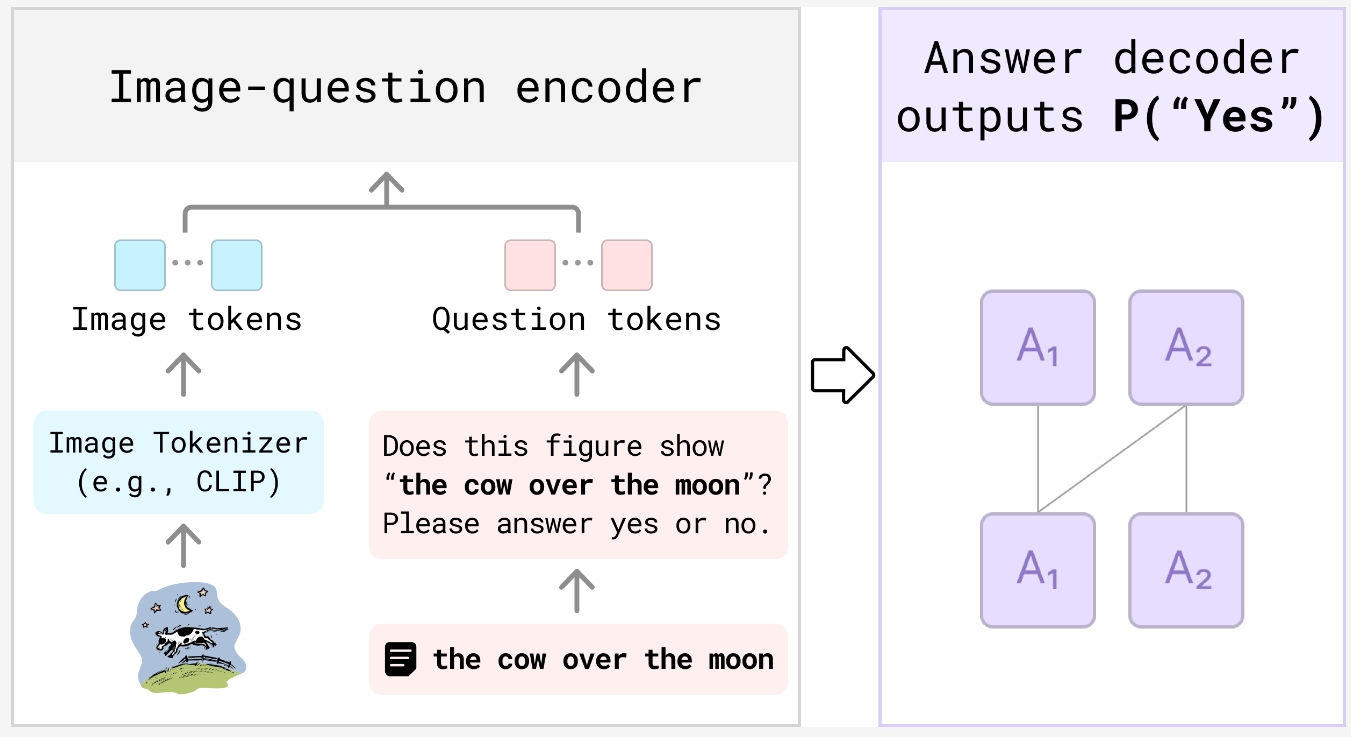
VQAScore 的工作原理
VQAScore 通过将文本提示转化为简单的问题来运作,例如“这张图像中有一只猫在追逐一只老鼠吗?”生成的图像与问题一起被 VQA 模型处理。模型确定答案是“是”还是“否”,VQAScore 根据 VQA 模型给出“是”的答案的可能性为文本到图像模型分配分数。
尽管方法看似简单,但其结果显著有效。研究人员在八个不同的文本到图像评估基准上测试了 VQAScore,发现其准确性和可靠性显著超过传统方法,甚至与基于先进模型如 GPT-4V 的评估相媲美。
此外,VQAScore 具有多功能性;不仅适用于文本到图像评估,还适用于 文本到视频 及 文本到 3D 模型评估。这种多功能性源于基础的 VQA 模型,能够处理各种类型的视觉内容。

GenAI-Bench:一个新的评估基准
除了 VQAScore,研究团队还建立了一个新的评估基准,称为 GenAI-Bench。该基准包括 1,600 个复杂的文本提示,测试各种视觉语言推理能力,包括比较、计数和逻辑推理。研究人员还收集了超过 15,000 条人类注释,以评估不同文本到图像模型的性能。
总之,VQAScore 和 GenAI-Bench 的推出 revitalizes 了文本到图像生成领域。VQAScore 提供了一种更准确和可靠的人工智能模型评估方法,使研究人员能够更好地理解各种系统的优缺点。同时,GenAI-Bench 提供了一个全面而具有挑战性的框架,鼓励开发更智能、更人性化的模型。
虽然 VQAScore 代表了一项重大进展,但也并非没有局限。目前,它主要依赖开源的 VQA 模型,其性能可能无法与像 GPT-4V 等闭源模型相匹配。预计未来 VQA 模型的改进将增强 VQAScore 的有效性。
有关更多信息,请访问项目页面:VQAScore 项目
要点
- VQAScore 提出了一个使用视觉问答评估文本到图像模型的新方法。
- 新的评估基准 GenAI-Bench 包括 1,600 个复杂的提示和超过 15,000 条人类注释。
- VQAScore 超越了传统评估方法,提供了生成 AI 模型更准确的评估。