Claude代码迎来速度飞跃:本地AI开发效率大幅提升
Claude代码的性能飞跃
在本地AI开发的重大进展中,JeecgBoot开发者的测试表明,当搭配社区改良版Gemma 4时,Claude Code运行速度显著提升。在Mac Studio M4Max环境下,改良配置实现了每秒78个token的生成速度——这是标准实现的5到6倍提升。
为何模型选择比优化更重要
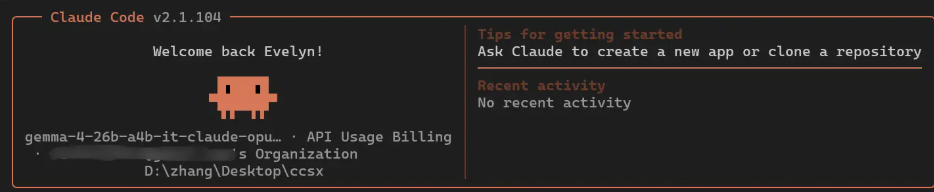
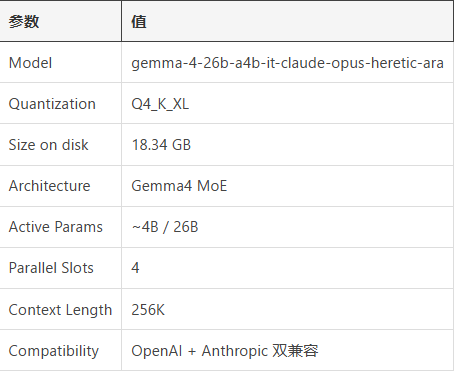
秘诀何在?开发者绕开官方模型,转而采用名为gemma-4-26b-a4b-it-claude-opus-heretic-ara的社区调校版本。这一替代方案展现出惊人能力:
- 极速输出:每秒78个token的速度碾压原版性能
- 高效架构:采用A4B MoE设计,每次推理仅激活260亿参数中的40亿
- 扩展内存:支持256K上下文窗口,同时保持与Anthropic API格式的兼容性
速度的权衡
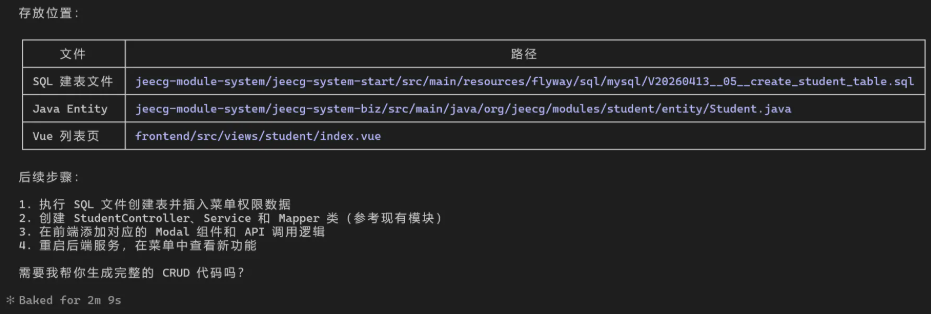
尽管原始生成速度令人印象深刻,开发者在实际应用中发现了一个有趣的现象:即使处理速度更快,完成特定任务(如生成教师表代码)仍需约90秒。瓶颈何在?Claude Code的多步决策流程。
"系统先思考再行动,这虽有利于代码质量,却增加了延迟,"一位开发者解释道。对于简单查询,他们推荐使用LM Studio等工具。
实际应用表现亮眼
在JeecgBoot框架项目测试中,Claude Code/Gemma组合展现了实用价值:
- 生成符合Flyway要求的标准化SQL
- 输出现代Vue3/TypeScript前端代码
- 创建完整的后端骨架(控制器、服务、映射器)
虽然复杂方法仍需人工优化,但该工具显著减少了模板代码编写。
智能部署策略
测试团队建议采用平衡方案:
- 本地模型(80%工作):适合常规CRUD操作和敏感内部项目
- 云端API(20%工作):更适用于复杂架构和安全关键组件
关键要点
- 改良模型推动本地AI开发达到新速度基准
- Claude Code/Gemma集成实现5-6倍性能提升
- 实际应用揭示速度与代理流程之间的权衡
- 混合部署策略平衡隐私、成本与质量
- 现代硬件使高性能本地AI日益普及