中国Qwen3.6 AI模型开源发布:小身材蕴藏大能量
开源AI领域的新竞争者
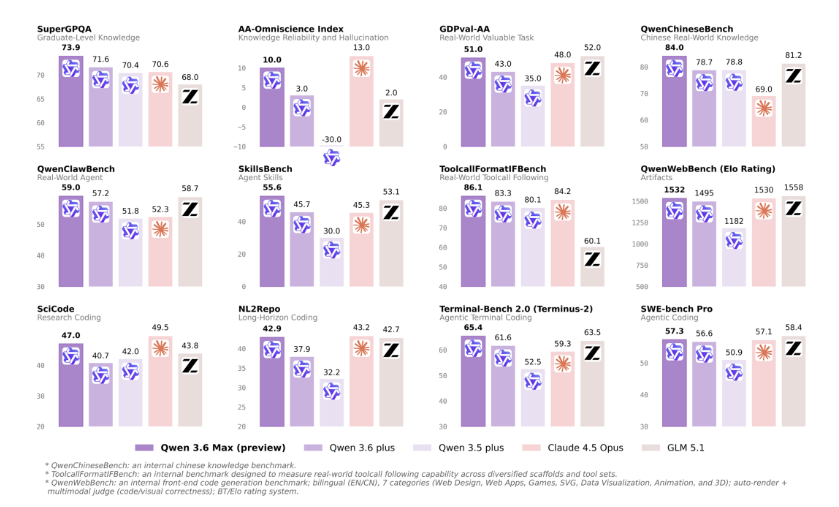
随着4月19日Qwen3.6-35B-A3B的开源发布,中国人工智能版图变得更加精彩。这款中等体量的模型表现远超其规模级别,将卓越能力与惊人效率完美结合。
小体积,大智慧
此次发布的特别之处何在?该模型通过先进的专家混合系统(MoE),仅在任何给定时间激活其350亿参数中的30亿。想象一下拥有一支专家团队,而你只需为需要的专家付费——这就是该架构的基本原理。对开发者而言,这意味着无需支付高昂计算费用即可获得顶级性能。
"这里的效率提升非常显著,"清华大学AI研究员李伟博士解释道,"你能用少得多的资源获得与更大模型相当的结果。"
基准测试颠覆者
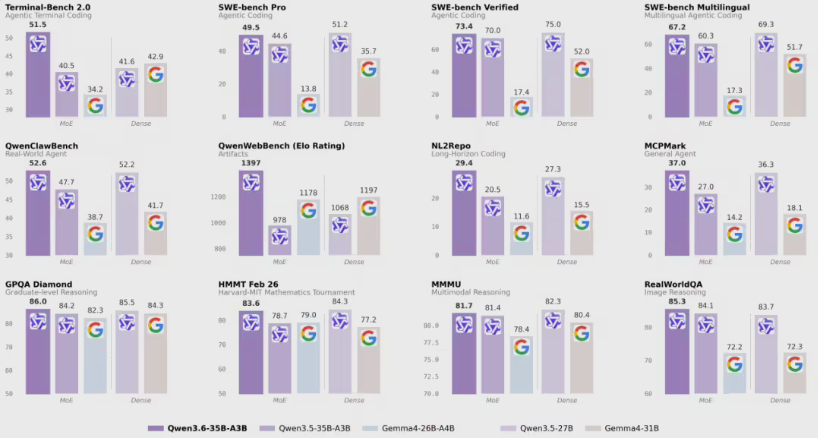
数据说明一切。在Terminal-Bench 2.0(测量编程能力)和现实世界代理测试中,Qwen3.6-35B-A3B不仅超越了前代产品——它甚至向两倍于自身规模的模型发起挑战。它的秘密武器?一种"多模态思维"模式,能以类人空间理解能力处理视觉信息。
想要证明?查看它在RefCOCO上的得分——在这个严苛的图像识别挑战中,它展现了对物理对象及其关系的惊人理解力。
为实际工作而生
这不仅仅是学术上的炫耀资本。开发者已确保其与OpenClaw和Claude Code等流行框架的深度兼容性。翻译过来就是:企业可以相对轻松地将其集成到现有系统中。
"我们看到制造和物流公司表现出浓厚兴趣,"阿里巴巴达摩院(Qwen背后的团队)的陈元指出,"编程智能与视觉理解的结合使其成为自动化复杂工作流程的理想选择。"
立即动手体验
最棒的部分?你不需要特殊权限或雄厚资金就能尝试。该模型现已通过以下平台提供:
- Mogu社区
- Hugging Face
- Qwen Studio
对于厌倦在性能与实用性之间做选择的开发者来说,这可能是他们一直在等待的'刚刚好'解决方案。
关键点:
- 高效架构 每次仅激活350亿参数中的30亿
- 超越 更大规模的模型在编程和现实代理测试中的表现
- 多模态能力 可同时处理文本和视觉信息
- 商业就绪 具备框架兼容性
- 即刻可用 通过主流开源平台获取