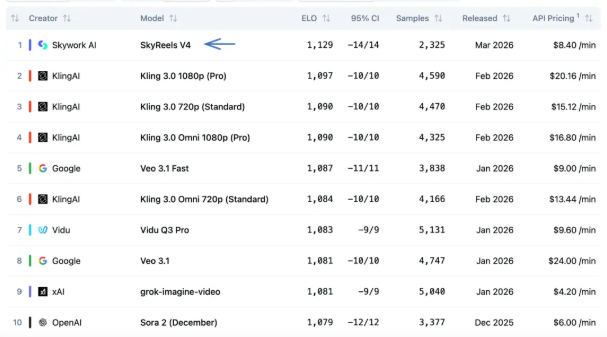
中国Qwen3.5-Max登顶全球AI排行榜,超越GPT和Claude
中国AI突破:Qwen3.5-Max领跑全球排行榜
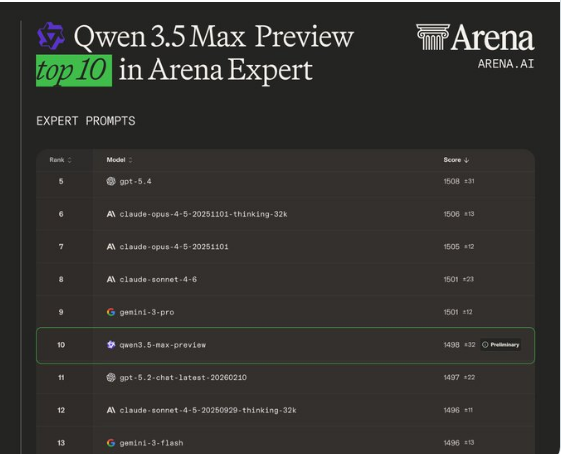
在人工智能领域掀起波澜的最新进展中,阿里巴巴的Qwen3.5-Max-Preview模型登上了权威LMArena基准测试的榜首。1464分的成绩不仅创下了中国自主研发模型的记录,更超越了包括OpenAI的GPT5.4和Anthropic的Claude4.5在内的所有国际主要竞争对手。
新AI势力格局
被誉为大语言模型评估黄金标准的LMArena盲测揭示了一个显著现象:全球前十席位中中国企业已占据五席。阿里巴巴作为中国的全球领跑者带头冲锋,字节跳动、智谱AI、月读暗面与百度共同组成了这支劲旅。
Qwen3.5-Max-Preview的制胜关键?其在逻辑推理和指令遵循方面的卓越表现让豆包2.0、Kimi2.5等国内竞品望尘莫及。更重要的是,这标志着中国AI能力已从追赶阶段迈入引领阶段。
超越数字游戏
全球AI竞赛规则已发生根本性转变。单纯依靠参数规模取胜的时代一去不返,当今的基准测试衡量的是真正重要的指标——模型在模拟真实用户需求的场景中的实际表现。
以Qwen为代表的中国模型正通过快速迭代周期和算法优化赢得全球开发者青睐。这已不仅是单项技术突破,更代表着在AI能力多维度上的系统性领先。
正如行业专家所指出的,我们正在见证全球AI竞争范式的重构——计算力与实际应用的结合方式或将重塑整个产业格局。
核心要点:
- 破纪录表现:Qwen3.5-Max-Preview以1464分问鼎LMArena,超越所有国际主流竞品
- 中国主导力:五家中国企业跻身全球AI模型性能前十强
- 竞争新时代:焦点从参数规模转向实际功能性与开发者采用度
- 行业影响:这些进步为大规模模型在各商业领域的广泛应用铺平道路