字节跳动与清华大学联合发布ChatTS,开创时序AI新突破
在人工智能领域的一次重大飞跃中,字节跳动与清华大学发布了ChatTS——一款尖端的时序多模态大模型(MLLM)。这一合作标志着AI处理与推理时间序列数据能力的里程碑,而这一能力长期困扰着传统模型。

由清华大学博士生谢哲领导的研究团队将学术严谨性与行业专长相结合。字节跳动科学家李泽彦、何晓与导师张铁英(字节跳动)、裴丹(清华大学)共同贡献了力量。他们的成果解决了一个长期存在的挑战:传统统计模型需要大量训练数据和复杂预处理,限制了其灵活性。
为何重要? 从股市预测到服务器性能监控,时序数据支撑着一切。然而迄今为止,AI系统在理解时间序列模式的自然语言方面仍举步维艰。ChatTS通过原生支持多变量时序推理改变了游戏规则——想象一下向AI提问“上周二服务器异常峰值的原因是什么?”并得到深刻解答的场景。
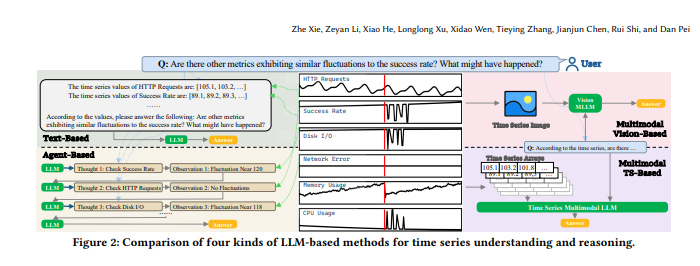
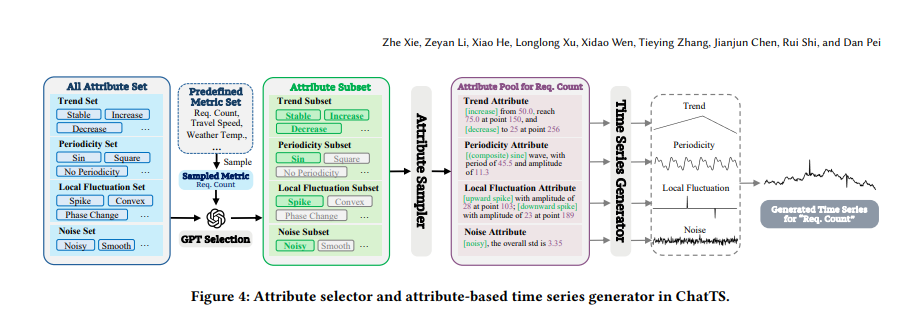
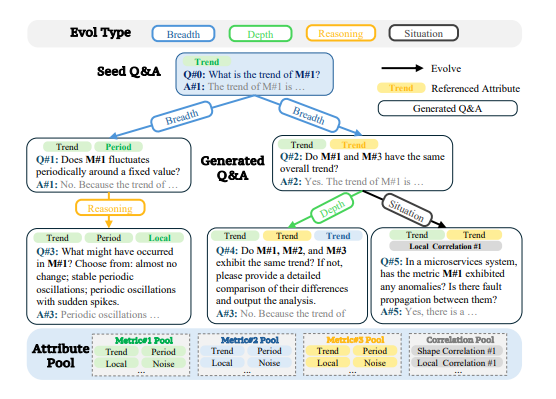
该团队首创了纯合成驱动方法,构建了一个端到端框架,可生成与精准自然语言描述配对的逼真时间序列数据。这一突破使ChatTS能够:
- 分析复杂的多变量模式
- 识别前所未见的波动
- 自动命名检测到的异常
在实际测试中,该模型展现出卓越的精确度。它无需明确提示即可提取异常波动——这一能力可能彻底改变金融欺诈检测或工业设备监控等领域。
行业专家预期其影响深远。“这不仅是又一个语言模型,”一位数据库研究员指出,“ChatTS弥合了原始时序数据与可操作洞察之间的鸿沟。”该技术的潜在应用包括:
- 实时金融市场分析
- 制造业中的预测性维护
- 自动化IT事件诊断
这项研究在计算机科学顶级会议VLDB2025上获得认可。随着企业日益依赖时效性数据,ChatTS正成为算法时代的重要工具。
关键要点
- ChatTS引入对时序问答的原生支持,克服了先前AI的局限
- 该模型利用合成数据生成确保语言-时间序列的精准对齐
- 已展示的能力包括无需明确训练的异常检测
- 潜在应用涵盖金融、IT运维和工业分析
- 研究获权威VLDB2025会议收录