百度发布PaddleOCR-VL,树立OCR技术新标杆
百度PaddleOCR-VL重新定义文档处理标准
百度正式发布其PaddleOCR-VL——一款尖端的多模态文档解析模型,为光学字符识别(OCR)技术设立了新的性能基准。这款开源模型在权威的OmniBenchDoc V1.5评估中以92.6分的成绩位居世界领先地位,展现出在文本识别、表格提取、公式解析和阅读顺序预测四大关键领域的卓越能力。
技术突破
这款0.9B参数的模型通过创新架构实现了高效能与高性能的结合:
- 集成NaViT动态分辨率视觉编码器与ERNIE-4.5-0.3B语言模型
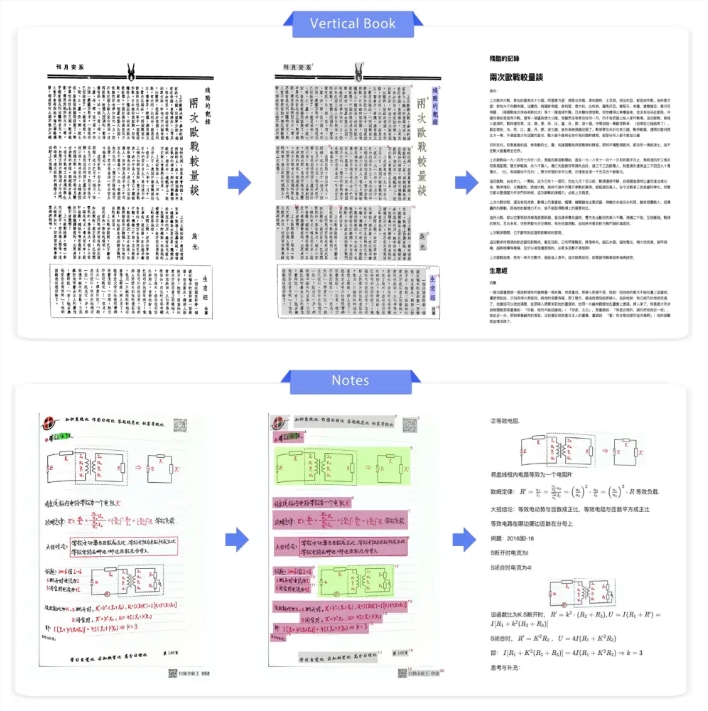
- 在单块A100 GPU上实现每秒处理1881个Token(比dots.ocr快253%)
- 支持包括阿拉伯语和中文等复杂文字在内的109种语言
性能指标
PaddleOCR-VL提供了前所未有的准确度:
- 文本编辑距离:0.035
- 公式识别(CDM):91.43
- 表格提取(TEDS):93.52
- 阅读顺序错误率:0.043
这些指标证明了其在历史档案数字化和手稿处理等挑战性应用中的可靠性。
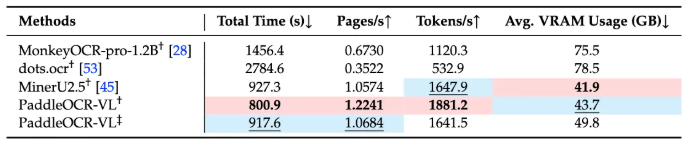
创新架构
该模型的两阶段方法彻底改变了文档理解方式:
- 版面检测与阅读顺序预测
- 输出结构化文本、表格和公式
这种方法使其能够像人类一样理解包括财务报告和学术论文在内的复杂文档,同时保持逻辑连贯性。
实际应用
该技术满足了跨行业的关键需求:
- 政府文件管理系统
- 企业知识检索平台
- 学术研究信息提取
- 历史档案保存项目
轻量化设计使其特别适合在资源受限的环境中部署。
关键亮点:
- 🏆 OmniBenchDoc V1.5测试世界领先(92.6分)
- ⚡ 超高效处理速度达1881 Tokens/秒
- 🌍 支持包括复杂文字在内的109种语言
- 🧠 类人类的文档版面理解能力
- 🔓 开源特性促进广泛采用


