苹果STARFlow-V以突破性方法撼动视频AI领域
苹果在视频生成竞赛中开辟新路径
在一项可能重塑视频AI格局的大胆举措中,苹果推出了STARFlow-V——这款视频生成模型突破了当前主流的扩散模型方法。这家科技巨头声称其标准化流技术在保证同等质量的同时,解决了一些长期存在的行业痛点。

STARFlow-V的差异化工作原理
当OpenAI的Sora或谷歌的Veo等大多数竞争对手使用需要多次迭代逐步优化视频的扩散模型时,苹果的系统只需一次训练步骤即可完成生成。"我们本质上是在教导模型学习随机噪声与复杂视频数据之间的直接数学变换,"一位苹果发言人解释道。据报道,这种方法减少了传统逐步生成过程中产生的误差。
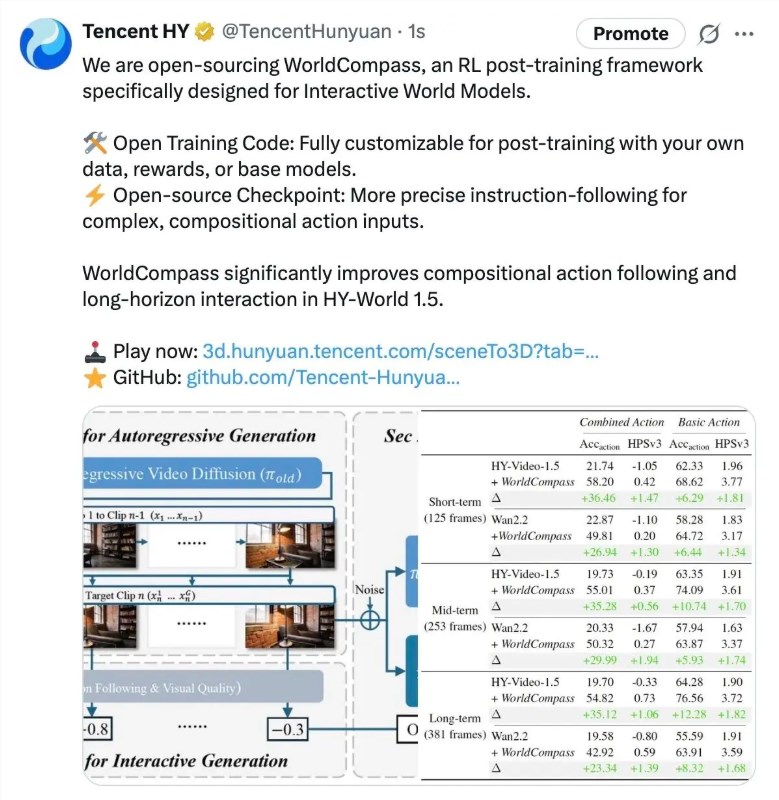
当前版本可输出640×480分辨率、16帧/秒的视频——这些参数与我们见过的某些更炫酷的演示相比可能显得保守。但STARFlow-V的优势在于长内容生成时的稳定性,这要归功于其新颖的滑动窗口技术,该技术能保持片段间的上下文连贯性。
实际应用前景广阔
该系统既能处理标准文本转视频指令,也能完成更专业的任务:
- 图像转视频(使用输入图像作为起始帧)
- 视频编辑功能
- 扩展序列生成
在演示过程中,该模型在保持空间关系和人体动作一致性方面表现出色——这是许多AI视频工具仍明显存在不足的领域。
底层技术创新
苹果工程师通过双重架构解决了长序列中常见的误差累积问题:
- 一个组件负责管理帧间时序关系
- 另一个组件优化单帧细节
团队还在训练阶段引入受控噪声以稳定优化过程,随后部署并行的"因果去噪网络"来消除伪影而不破坏运动一致性。
训练方案同样雄心勃勃——向模型输入7000万组文本-视频对,并补充400万组文本-图像对。语言模型将每个视频描述扩展为九种变体以提高学习效率。
发展空间显著
基准测试显示STARFlow-V在VBench上获得79.7分——略逊于顶级扩散模型,但对于这种新方法已属惊艳。苹果承认目前在输出多样性方面存在局限,未来开发将聚焦于:
- 提升计算速度
- 优化物理准确性
- 扩展训练数据集
尽管行业趋势如此,该公司似乎仍坚持这条替代性技术路线,押注其方法对专业工作流程的优势将随时间推移赢得更多支持者。
关键要点:
- 🎥 创新方法:采用标准化流而非扩散模型实现单步生成
- ⚡ 效率优势:减少迭代过程中常见的误差累积
- 🛠️ 多功能工具集:以惊人一致性处理创作与编辑任务
- 📈 未来重点:物理精确性与速度优化即将到来