Anthropic开源AI透明度工具,助力解读模型决策过程
人工智能研究公司Anthropic在提升AI系统透明度方面迈出了重要一步,发布了其开源的"Circuit Tracing"工具。这项于5月29日宣布的创新技术为研究人员提供了一种可视化和分析大型语言模型(LLMs)决策过程的方法。
可视化AI思维过程
Circuit Tracing工具创建了详细的归因图,描绘了信息从输入到输出在AI系统中的流动路径。这些图表揭示了模型在生成响应时优先考虑的特征和模式——本质上展示了AI决策背后的"思维过程"。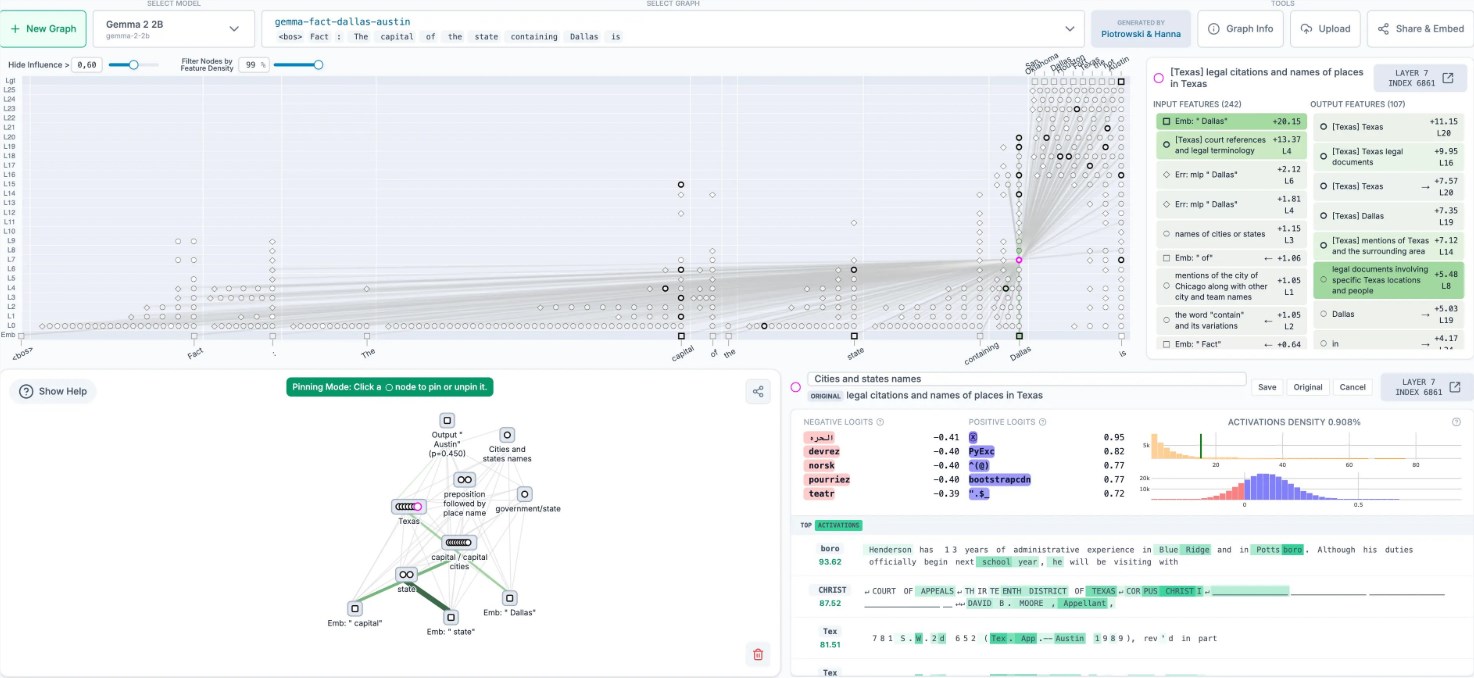
"这为我们提供了一种显微镜,以前所未有的方式检查神经活动,"一位Anthropic研究员解释道。该工具识别了特定输入触发特定输出的关键决策点,帮助开发人员理解为什么模型有时会产生意外或有偏见的结果。
与Neuronpedia的交互分析
为了使这些发现更易获取,Anthropic集成了一个名为Neuronpedia的交互式前端。研究人员现在可以:
- 实时调整输入参数
- 跟踪变化如何影响模型输出
- 测试关于模型行为的假设
该界面甚至允许非专家通过直观的可视化探索复杂的神经网络。详细的指南帮助用户导航系统并准确解释结果。
打开黑匣子
随着语言模型被部署到医疗、金融和法律系统等敏感领域,AI透明度变得越来越重要。Anthropic的开源方法使更广泛的解释性研究合作成为可能,同时解决了日益增长的担忧:
- 模型输出中的潜在偏见
- 幻觉或虚假信息生成
- 不透明决策的伦理影响
该项目是通过Anthropic Fellows计划与Decode Research合作开发的,展示了学术合作如何推动负责任的AI发展。
这对AI未来意味着什么
行业专家认为Circuit Tracing可能是构建可信赖AI系统的潜在变革者。随着模型变得更加透明:
- 开发人员可以更有效地优化性能
- 组织可以实施更好的错误防护措施
- 监管机构获得了评估系统可靠性的工具
该技术还可能通过提供关于模型实际功能的具体数据(而不是依赖理论框架)来影响正在进行的AI治理辩论。
关键要点
- Anthropic的Circuit Tracing工具可视化了大型语言模型中的决策路径
- Neuronpedia交互界面允许实时实验模型参数
- 开源发布使更广泛的AI可解释性和安全性研究成为可能
- 该技术解决了关于偏见、幻觉和伦理部署的关键问题
- 可能为日益强大的AI系统建立新的透明度标准