Anthropic发布Claude Opus 4.1,增强AI能力
Anthropic发布Claude Opus 4.1,增强AI能力
Anthropic正式推出Claude Opus 4.1,这是其旗舰AI模型的最新版本,在Agent任务、实际编码和推理能力方面实现重大进步。作为Claude Opus 4的直接升级版,新版本现已通过API、Amazon Bedrock和Google Cloud的Vertex AI向付费用户开放。
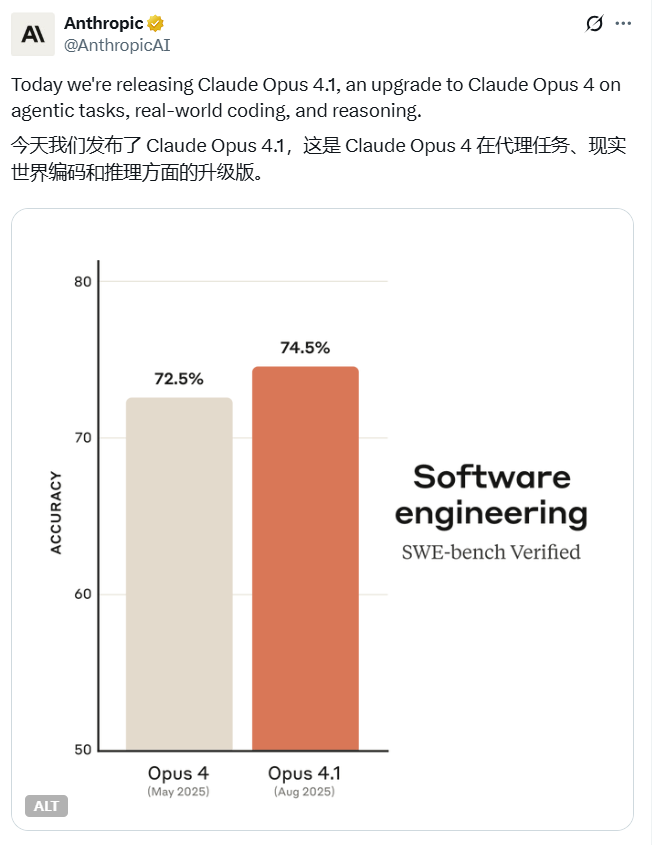
性能基准测试
Claude Opus 4.1在SWE-bench Verified软件工程基准测试中获得了74.5%的分数,较上一版本的72.5%有所提升。该模型在多文件代码重构、精确调试和复杂任务执行方面表现出色。根据GitHub的数据,它在大多数能力上优于前代版本,尤其是在高效处理大型代码库方面。
乐天集团报告称,该模型能准确识别大型代码库中的错误,最大限度地减少不必要的调整并降低bug引入率——从而提升日常调试效率。
Agent任务与推理升级
该模型在TAU-bench和GPQA Diamond等基准测试中展现出更强的多步推理能力和细节追踪能力,使其非常适合长期自主操作。Anthropic强调其分析复杂数据源(如专利数据库、学术论文和市场报告)的能力,可为决策提供战略洞察。
Claude Opus 4.1还支持高达64K tokens的上下文窗口扩展推理功能,从而更准确地处理冗长信息。
开发者的无缝升级体验
升级至Claude Opus 4.1设计简洁:开发者只需将模型字符串从claude-opus-4-20250514更新为claude-opus-4-1-20250805,无需更改API配置。定价保持不变:输入token为每百万15美元,输出token为每百万75美元;同时新增了节省成本的功能如提示缓存(最高可节省90%)和批量处理优化(成本降低50%)。
安全性与稳定性承诺
Anthropic强调Claude Opus 4.1的安全性:无害响应率达到98.76%(此前为97.27%),拒绝率低至0.08%。严格测试确保该模型在生物风险和网络能力等领域始终低于高风险阈值。
行业竞争与未来计划
此次发布正值AI开发竞争加剧之际。Anthropic首席产品官Mike Krieger指出行业正从重大升级转向渐进式改进。公司还透露将在未来几周推出“更大规模的模型改进”。
此次发布巩固了Anthropic相对于OpenAI等竞争对手的地位——后者据传正在开发GPT-5。
关键点总结
- 编码性能增强: SWE-bench Verified得分74.5%。
- 推理能力提升: 擅长多步任务和长上下文分析。
- 经济高效: 保持原价同时通过缓存和批量处理节省成本。
- 注重安全: 无害响应率98.76%,拒绝率仅0.08%。
- 无缝集成: 为开发者提供简易升级路径。