蚂蚁集团最新AI模型为多模态技术树立新标杆
蚂蚁集团开源突破推动多模态AI向前发展
在AI界的重要举措中,蚂蚁集团于2月11日将Ming-Flash-Omni 2.0作为开源软件发布。这一先进的多模态模型不仅仅是渐进式更新——它正在设定新的基准,在某些性能指标上甚至挑战了谷歌的Gemini 2.5 Pro。
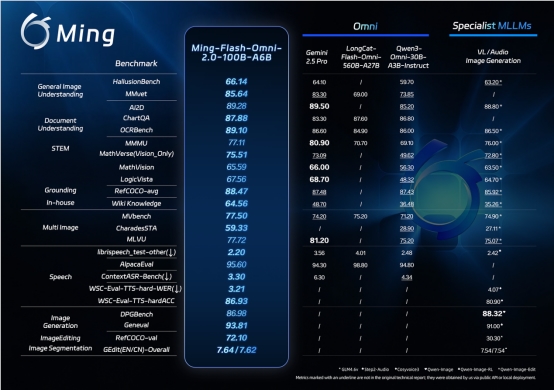 (说明:Ming-Flash-Omni-2.0在视觉语言处理和多媒体生成方面展现出领先能力。)
(说明:Ming-Flash-Omni-2.0在视觉语言处理和多媒体生成方面展现出领先能力。)
听觉革新
本次发布尤其引人注目的是其音频能力。开发者现在可以实现诸如"让声音听起来带南方口音且情绪激动"或"在钢琴旋律下添加雨声"这样的自然语言指令。该模型以显著效率处理这些复杂音频任务,仅以3.1Hz帧率就能生成分钟级高保真音频。
视觉提升
视觉改进同样令人印象深刻。团队向系统输入了数十亿细粒度样本,使其在棘手识别任务中表现卓越——无论是区分相似犬种还是识别文物中的复杂工艺细节。
蚂蚁集团百灵模型团队负责人周俊阐释其理念:"真正的多模态技术不应像是拼凑起来的独立工具。我们构建了统一架构,使视觉、语音和生成能力自然相互增强。"
开发者的实际收益
对于构建AI应用的开发者而言:
- 简化工作流:无需再拼接专用模型
- 降低成本:单一模型效率减少计算开支
- 创意可能:开辟多媒体内容生成新领域
模型权重和推理代码现已在Hugging Face及蚂蚁的灵玑平台开放获取。
未来展望
团队并未止步于此。未来更新将聚焦:
- 增强视频时间线理解能力
- 更精细的图像编辑工具
- 改进实时长音频生成效果
此次发布标志着向更集成化多模态系统的重要转变——这类系统或许终将实现像人类一样全面理解世界的AI愿景。
关键要点:
- 行业领先性能:通过多项基准测试验证
- 首个统一音频模型:可同步处理语音、音效和音乐
- 自然语言控制:可调节情感、方言等声音参数
- 开源可用性:降低全球开发者使用门槛