蚂蚁集团最新AI模型在多模态技术领域取得突破
蚂蚁集团开源AI模型树立新标杆
在AI界的重要举措中,蚂蚁集团于2月11日将其Ming-Flash-Omni 2.0模型开源发布。这不仅是常规迭代更新——基准测试表明它正在为开源多模态AI的能力树立新标准。
前所未有的视觉、听觉与创作能力
该模型在三个关键领域表现突出:
- 视觉理解:能区分几乎相同的动物或发现细微的手工细节
- 音频生成:可在单条音轨上无缝融合语音、音效和音乐
- 图像编辑:能进行复杂修改同时保持真实细节
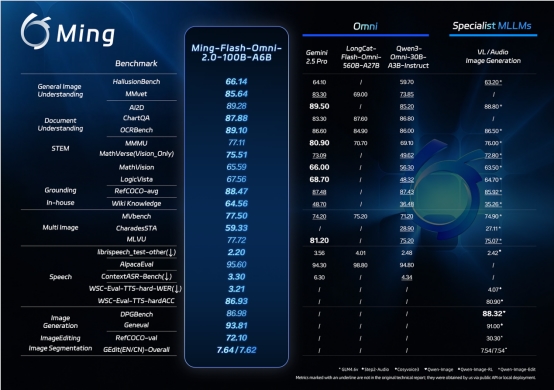 (说明文字:Ming-Flash-Omni-2.0在视觉理解、音频生成和图像编辑能力方面领先)
(说明文字:Ming-Flash-Omni-2.0在视觉理解、音频生成和图像编辑能力方面领先)
这对开发者有何特别意义?蚂蚁集团百灵团队的周军解释道:「我们构建了统一架构,不同能力实际会相互增强。就像给开发者瑞士军刀而非分散的工具。」
对开发者的重要意义
此次开源意味着现在任何人都可以:
- 以超低3.1Hz帧率实时生成长达一分钟的音频
- 使用简单自然语言指令微调声音参数(试试说「让它听起来更兴奋些,带南方口音」)
- 一键完成复杂图像编辑如场景替换或光线调整
「多数多模态模型迫使你在专业化与通用化间做选择,」一位行业分析师指出,「蚂蚁集团似乎同时攻克了两者——既与专业模型竞争又保持广泛能力。」
该技术基于蚂蚁集团的Ling-2.0架构,整合了数十亿数据点。团队重点优化了模型的:
- 视觉识别更高精度(特别是罕见或复杂物品)
- 音频生成更准确(具备零样本声音克隆功能)
- 图像编辑更稳定(即使是动态场景)
未来展望?
Ming-Flash-Omni系列已从建立基础多模态能力发展到引领开源领域。未来更新将攻克视频理解和更长音频生成。
模型权重和代码已在Hugging Face发布,演示版可通过蚂蚁的灵玑平台访问。
关键要点:
- 开源优势:降低开发多模态应用的门槛
- 音频突破:首个统一处理语音、音效和音乐的模型
- 视觉精度:识别多数模型忽略的细节
- 开发者友好:统一框架降低集成复杂度