阿里巴巴新算法助力AI更接近人类思维
阿里巴巴通义实验室在AI推理领域取得突破
阿里巴巴通义实验室的研究人员开发出一种创新算法,可能彻底改变人工智能处理复杂推理任务的方式。这项名为FIPO(Future-KL Influenced Policy Optimization)的新方法,解决了大语言模型在处理多步骤问题时的一个根本性挑战:如何识别哪些信息才是真正重要的。
推理瓶颈问题
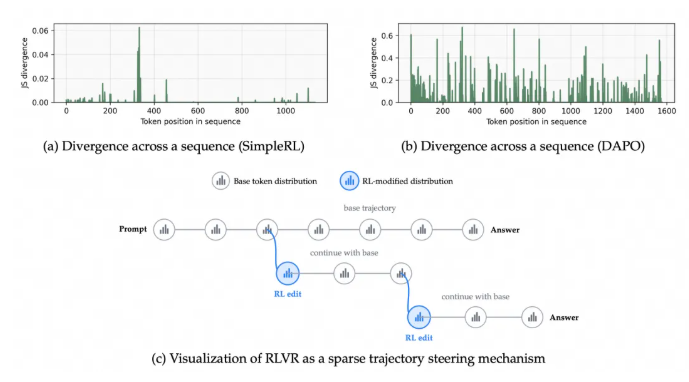
当前的强化学习方法在处理长推理链时往往对所有信息一视同仁。"想象一下在解数学题时无法分辨哪些数字会影响最终答案",一位熟悉该项目的研究人员解释道,"这本质上就是这些模型面临的挑战。"
FIPO算法引入了团队所称的"Future-KL"机制。这种巧妙的方法专门奖励那些对后续推理步骤至关重要的token(AI系统中的基本信息单位)。就像在计算过程中给真正导向解决方案的步骤加分,而不是对所有步骤同等对待。
实际表现
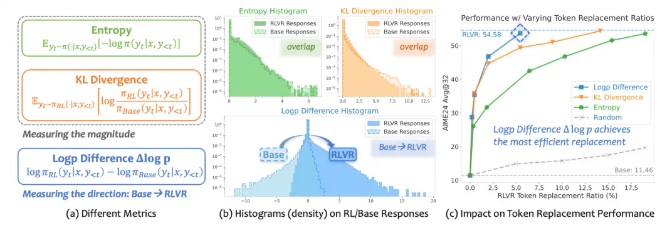
在实际测试中,FIPO展现出卓越的效果。应用于阿里巴巴的Qwen2.5-32B-Base模型时,其平均推理长度超过10,000个token——这是一个重大突破。更重要的是,它不仅能够处理更长的推理链,而且在复杂数学问题上表现得更加准确。
在纯强化学习环境中,该算法表现优于o1-mini和DeepSeek-Zero-MATH等同类模型。这些成果特别有趣的地方在于其实现方式:通过聚焦研究人员所称的"优化方向性"——本质上是教会AI识别问题解决过程中的有效路径。
重要意义
传统AI训练中的大多数token在学习前后变化极小——研究人员称之为"极度稀疏"的影响效果。常见的评估指标往往忽略了关键token中微妙但至关重要的变化。FIPO通过引入Δlog p(符号对对数概率差异)作为新的衡量标准,让开发者能更清晰地了解模型的学习过程。
这一突破出现在AI系统被越来越多地要求处理复杂多步推理任务的时代——从科学研究到金融分析皆如此。区分关键信息与非关键信息的能力,可能是开发更可靠、更强大AI助手的关键所在。
要点总结:
- 智能聚焦: FIPO帮助AI识别并优先处理推理任务中最关键的信息
- 更长推理: 支持处理超过10,000个token长度的推理链
- 更高准确率: 在复杂数学问题求解方面展现显著提升
- 新评估标准: 引入Δlog p作为追踪学习进度的更有效方法