AI的意外困境:为何六岁儿童能胜过顶级模型
当儿童超越AI:视觉推理的鸿沟
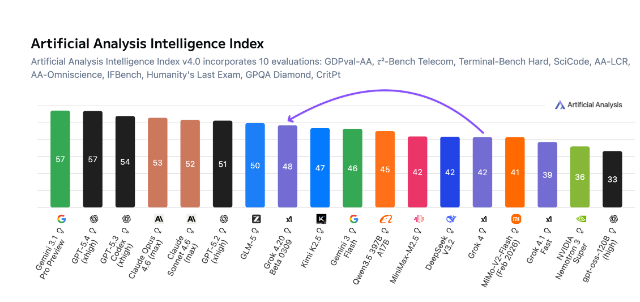
人工智能或许能在国际象棋和数学竞赛中称霸,但在视觉推理领域,学龄前儿童仍占据绝对优势。来自UniPat AI和阿里巴巴等机构的惊人新研究显示,顶级AI模型在基础视觉任务中的表现仅略优于幼儿。
BabyVision带来的警醒
研究团队开发的BabyVision视觉推理测试,暴露了AI感知世界时的根本局限。当人类儿童能轻松发现差异或解决空间谜题时,即便是当前领先领域的Gemini 3 Pro Preview——在面对多数六岁儿童认为简单的任务时也举步维艰。
迷失在转换中
核心问题在于:当前的大模型本质上仍是"语言动物"。处理图像时,它们会先将视觉信息转换为文字描述再进行推理。这种间接方法适用于宽泛概念,但在处理微妙视觉细节(如轻微曲线变化或复杂空间关系)时表现糟糕。
AI视觉缺陷的四大表现
研究将AI的视觉短板归纳为四个关键领域:
- 细节缺失困境:像素级差异常被AI忽视,导致形状匹配任务出错
- 迷宫跑偏现象:如同分心的孩童,模型在轨迹追踪时会迷失于交叉路口
- 空间想象力缺口:文字描述无法准确呈现3D空间,造成频繁的投影错误
- 模式盲区:模型机械计算属性而非理解演化规律,缺乏深层逻辑把握
对具身智能的启示
这些发现给雄心勃勃的具身AI助手计划泼了冷水——如果机器无法达到儿童对物理环境的理解水平,我们如何放心让它们安全导航世界?
研究提出两种潜在解决方案:
- 采用强化学习方法(RLVR),融入显式中间推理步骤
- 开发真正的多模态系统(类似Sora 2的方案),直接在像素空间进行"视觉计算"而非依赖语言转换
这项研究给出了发人深省的提醒:通往通用人工智能的道路或许不在于解决更难的数学题,而在于掌握儿童喜爱的简单谜题。