AI编程基准测试可能描绘出比现实更美好的图景
AI编程助手的现实检验
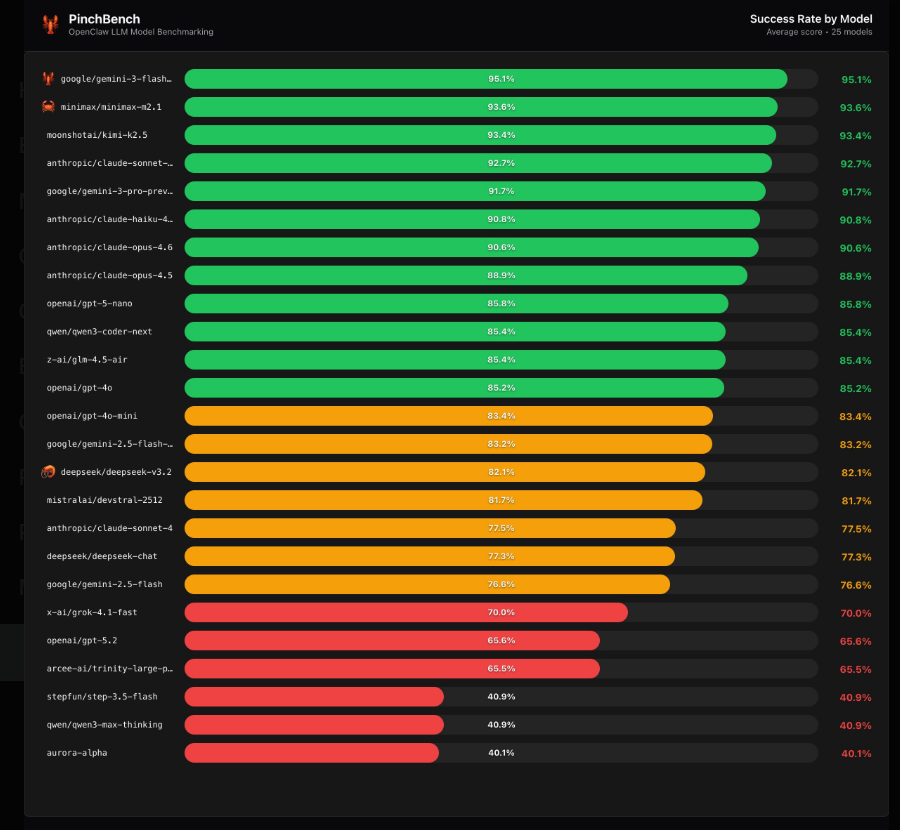
您最爱的AI编程助手展示的那些光鲜基准分数?它们可能没有讲述完整的故事。METR机构的最新研究传递了一个发人深省的信息:广泛使用的SWE-bench Verified基准可能以惊人幅度高估了AI的编程能力。
当自动化测试遇上人类判断
该研究对五款领先AI模型(包括Claude和GPT系列)进行了严格测试。研究人员向scikit-learn和pytest等热门开源项目的维护者提交了296份AI生成代码。他们的发现挑战了我们对自动化基准的依赖:
- 自动化评分与人类认可率之间存在24个百分点的差距
- 近半数"通过"的解决方案在实际审查中被否决
- 即使是通过自动化检查的代码仍存在功能错误
这些问题不仅关乎风格偏好。维护者指出了三大主要问题领域:
- 代码质量违规(不符合项目特定标准)
- 结构破坏(打乱现有代码架构)
- 基本功能错误(解决方案实际上无法工作)
模型比较的意外发现

研究揭示了不同AI模型间的有趣模式:
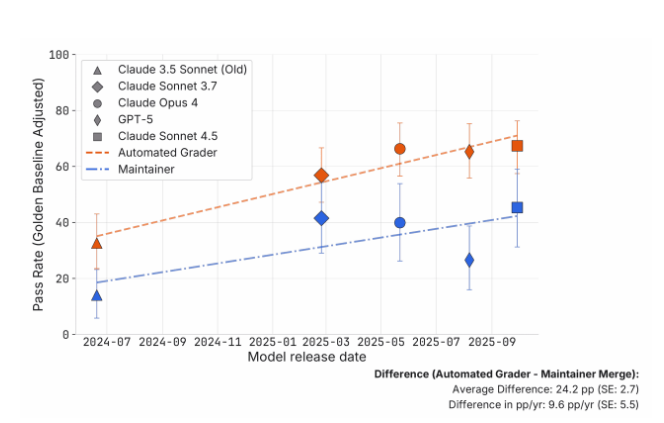
- 虽然Claude升级版在基准测试中有所改进,但某些版本引入了更多功能错误
- GPT-5在此次评估中表现意外逊色于Anthropic的模型 最惊人的发现?基准分数可能将真实能力夸大了七倍之多。当自动化测试显示Claude4.5Sonnet能完成需要50分钟人工努力的任务时,维护者的评估表明实际上仅需8分钟。
这对开发者的重要意义
其影响远超学术兴趣范畴:
- 依赖AI编程助手的团队应根据基准声明调整期望值
- 当前评估方法可能无法捕捉真实开发工作流的细微差别
- 亟需能反映实际工程环境的更好测试框架
研究人员强调这并不意味着AI编码工具触及了根本极限——只是我们的测量系统需要改进。通过更好的提示策略、迭代反馈循环和更真实的测试场景,基准与现实之间的差距有望缩小。
关键要点
- SWE-bench Verified可能高估了AI编码能力,描绘出比现实更美好的图景