AI编程助手大比拼:谁才是真正的实力派?
AI编程助手迎来现实检验
科技界正热议最新发布的OpenClaw排名——这项务实的评估让AI编程助手们经历了严苛考验。与理论基准不同,该测试衡量的是这些工具在真实编程任务中的实际表现。
测试方法解析
OpenClaw框架采用智能双重校验系统:自动代码验证结合AI审查。这既消除了人为偏见,又确保每个模型都面临同等难度的挑战。"我们希望创建反映开发者真实需求的评测标准,"项目团队解释道,"重点不是谁能写出最花哨的代码——而是谁能交付可用的解决方案。"
脱颖而出的佼佼者
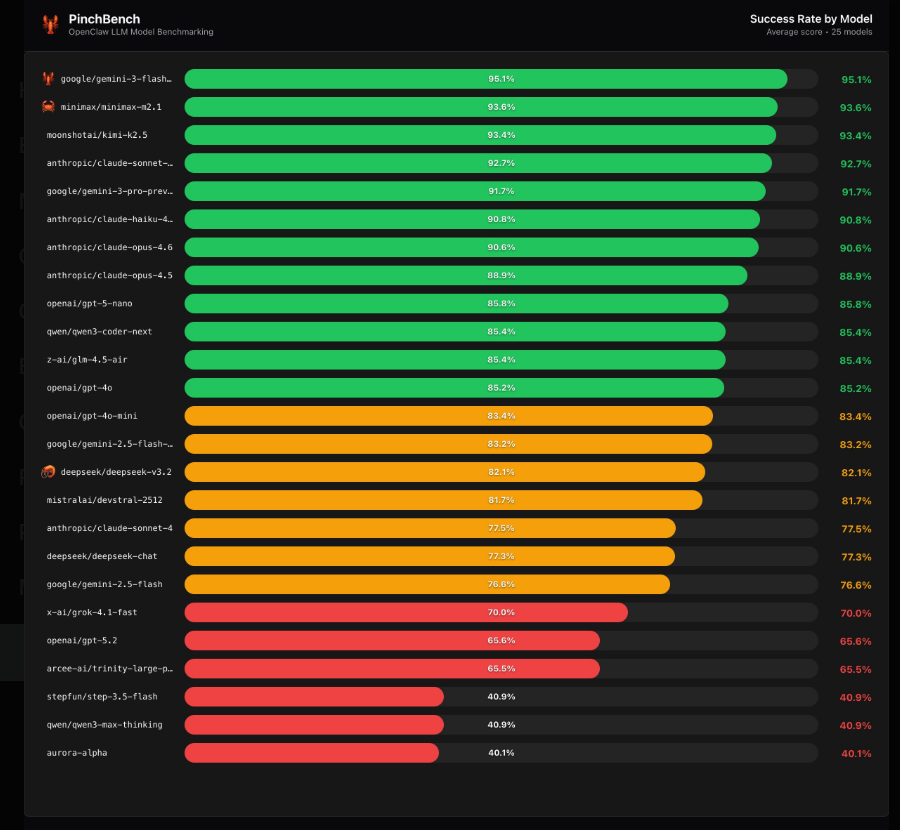
三大模型成为明显领跑者:
- Gemini3Flash预览版 以稳定可靠的输出拔得头筹
- MiniMax M2.1 处理复杂逻辑的能力令人印象深刻
- Kimi K2.5 凭借全面表现跻身前三甲
但最引人注目的或许是Claude模型家族,它们以超过90%的成功率集体占据中上游位置。其处理多步骤编码挑战的能力显示出在企业应用方面的独特优势。
意外折戟的选手
评测也爆出冷门:尽管参数规模庞大,GPT-5.2仅取得65.6%的成功率——远低于人们对这个知名模型的预期。而DeepSeek V3.2则以82%的成绩徘徊于平均水平。
"这些结果印证了许多开发者的怀疑,"一位行业分析师指出,"原始计算能力并不总是等同于实际编码能力。"
对开发者的启示
OpenClaw排名提供了AI领域罕见的东西:关于哪些工具能在压力下真正工作的清晰、可操作数据。对于选择编程助手的团队而言,这些结果意味着:
- 选择经过验证的工具可提升生产力
- 减少不可靠输出导致的调试困扰
- 更有信心实施AI辅助工作流
团队计划随着模型演进每季度更新排名。
核心要点:
- 真实场景测试 揭示哪些AI编程助手能交付可用方案
- Gemini3Flash领跑 Claude系列展现超强稳定性
- 意外落后者证明并非越大越好
- 开发团队选型具有实际指导意义