AI重大突破:新型架构为跨数据中心语言模型注入强劲动力
现代AI面临的计算瓶颈
随着人工智能系统日趋复杂,它们正面临实质性的性能瓶颈。当今大型语言模型(LLM)的巨大计算需求正压垮传统数据中心架构。想象试图通过吸管倾倒一加仑水——这正是AI开发者当前面临的挑战。
巧妙的职责分工
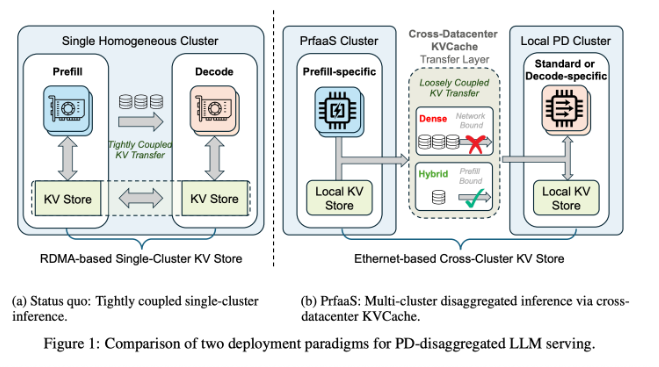
Moonshot AI与清华大学合作提出名为预填充即服务(PrfaaS)的优雅解决方案。该架构认识到LLM处理自然分为两个不同阶段:
- 预填充阶段 - 模型处理输入数据(计算密集型)
- 解码阶段 - 生成响应(内存带宽密集型)
"现有系统强制两个流程在同一数据中心完成,"项目首席研究员李文博士解释,"这就像让主厨在狭小厨房里同时备菜和摆盘。"
PrfaaS如何改变格局
这项突破性技术通过地理隔离实现任务分配:
- 繁重计算由专为数值运算优化的计算集群处理
- 解码在靠近终端用户的本地数据中心进行
- 中间产物键值缓存(KVCache)通过标准以太网高效传输
初步结果令人振奋——与传统方法相比吞吐量提升54%,延迟显著降低。实际应用中,这意味着即使在高峰使用时段,您的AI助手也能更快响应。
更智能的资源管理
该架构在资源分配方面引入多项创新:
- 精确路由机制防止数据传输拥堵
- 双时间尺度调度动态适应工作负载变化
- 计算、网络和存储子系统的独立管理
"最令人兴奋的是,"清华大学的陈博士表示,"是其可扩展性。当新硬件出现时,我们可以将其接入系统相应部分而无需重新设计整体架构。"
AI基础设施的未来
随着AI应用呈指数级扩张,PrfaaS这类解决方案的出现恰逢其时。该方法不仅解决当前限制,更为未来创新提供灵活框架。当企业对其AI系统提出更高要求——用户期待更快响应时——这种架构或将成为新标准。
关键要点
- 解决问题: PrfaaS突破大型语言模型的计算瓶颈
- 工作原理: 将预填充与解码阶段分配至优化数据中心
- 性能提升: 吞吐量提高54%,延迟降低
- 智能特性: 先进路由和动态调度避免拥堵
- 面向未来: 设计兼容新兴硬件技术





