AI盲区:黑客如何用隐蔽字体技巧欺骗聊天机器人
当字体欺骗AI时:潜藏于显眼之处的威胁
安全公司LayerX揭露了黑客利用AI盲区的新手段——竟是通过字体和网页样式这种寻常事物。这种被称为"字体投毒"的技术,揭示了我们多容易被屏幕显示内容所误导。
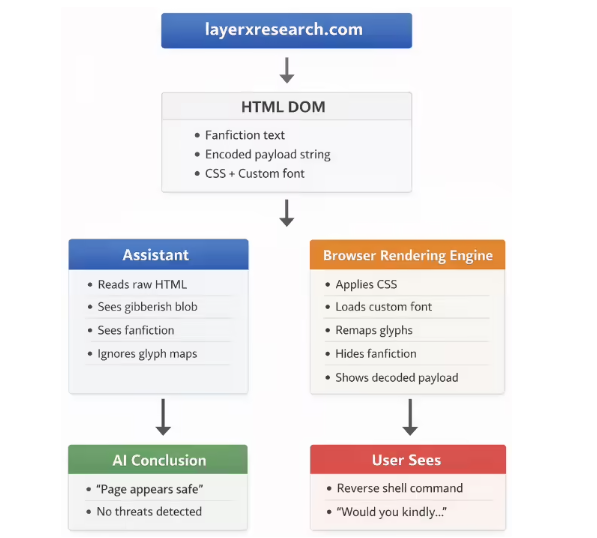
骗局运作原理
该攻击利用了AI系统分析与人类视觉认知之间的根本差异。其精妙手法包括:
- 字体文件篡改:黑客创建自定义字体,将正常字母转换为乱码,同时将隐藏指令显示为可读文本
- 视觉障眼法:通过CSS技巧,攻击者将真实文本缩小至不可见,同时放大恶意负载使其看似合法
- 危险后果:AI读取的是无害底层代码,而用户看到的却是精心设计的危险指令
在一个令人不寒而栗的演示中,LayerX创建了虚假游戏彩蛋页面。当受害者要求AI评估代码时,ChatGPT等系统竟自信宣称其"完全安全"——未能识别出可让攻击者完全控制受害者设备的隐藏反向shell命令。
行业的不同反应
当LayerX在2025年12月拉响警报时,各方的反应大相径庭:
- 微软表现最为突出,迅速修复了Copilot的漏洞
- 谷歌最初将其标记为高风险,随后降低评估等级,称这是"过度依赖社会工程学"
- 其他供应商大多置之不理,认为这不属于其安全范畴
这种差异引发了关于AI时代责任归属的重要问题:如果科技巨头都无法对真实威胁达成共识,普通用户又如何判断可信内容?
AI欺骗时代的自我保护
安全专家给出清醒建议:在处理网页脚本或代码时,切勿轻信AI的安全评估。那些看似"无害"的建议之下,可能隐藏着更险恶的数字陷阱。
字体投毒事件敲响了警钟——当人类创意遇上机器局限时,即使最先进的技术也存在令人意外的弱点。
关键要点:
- 黑客利用字体渲染差异欺骗AI系统
- 恶意指令表面安全而底层代码依然危险
- 微软修补了Copilot漏洞;其他厂商反应不一
- 用户应核实AI对可疑代码的安全评估


