ZeroSearch Cuts LLM Retrieval Costs by 88% in Breakthrough
A joint research team from Qwen Lab and Peking University has unveiled ZeroSearch, an innovative framework that dramatically reduces the cost of training retrieval capabilities in large language models (LLMs). The breakthrough technology achieves an 88% cost reduction by eliminating dependency on actual search engine queries during training.
Traditional LLM training methods typically rely on expensive API calls to real search engines, which not only drive up costs but also introduce performance inconsistencies due to variable result quality. ZeroSearch circumvents these challenges by using the LLM itself as a "simulated search engine", leveraging its pre-trained knowledge base to generate retrieval documents instead of querying external sources.
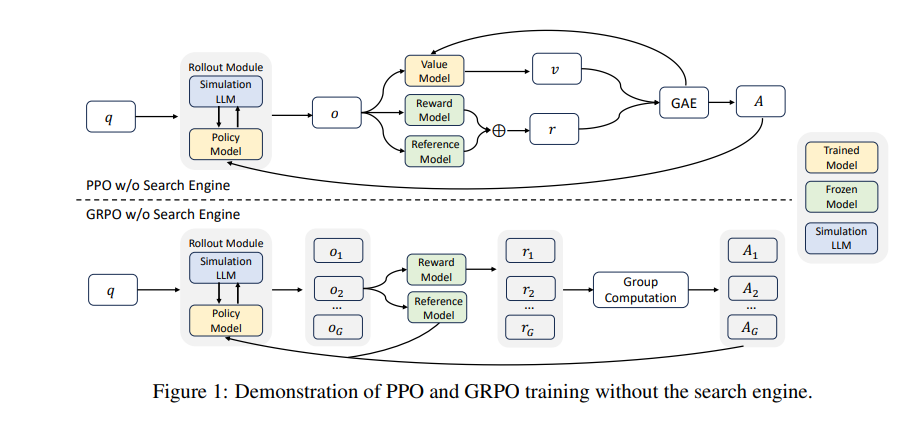
The framework employs a structured training template that guides the model through logical reasoning steps, enhancing both clarity and efficiency. This systematic approach improves answer extraction while maintaining coherent reasoning paths. Through a technique called "simulation fine-tuning," ZeroSearch further refines output quality, ensuring generated documents meet practical application standards.
Experimental results demonstrate ZeroSearch's superior performance compared to traditional search-dependent methods. The framework shows remarkable generalization capabilities and stability, with performance scaling positively as model size increases. Researchers note this advancement could reshape how developers approach LLM training for information retrieval tasks.
Resources:
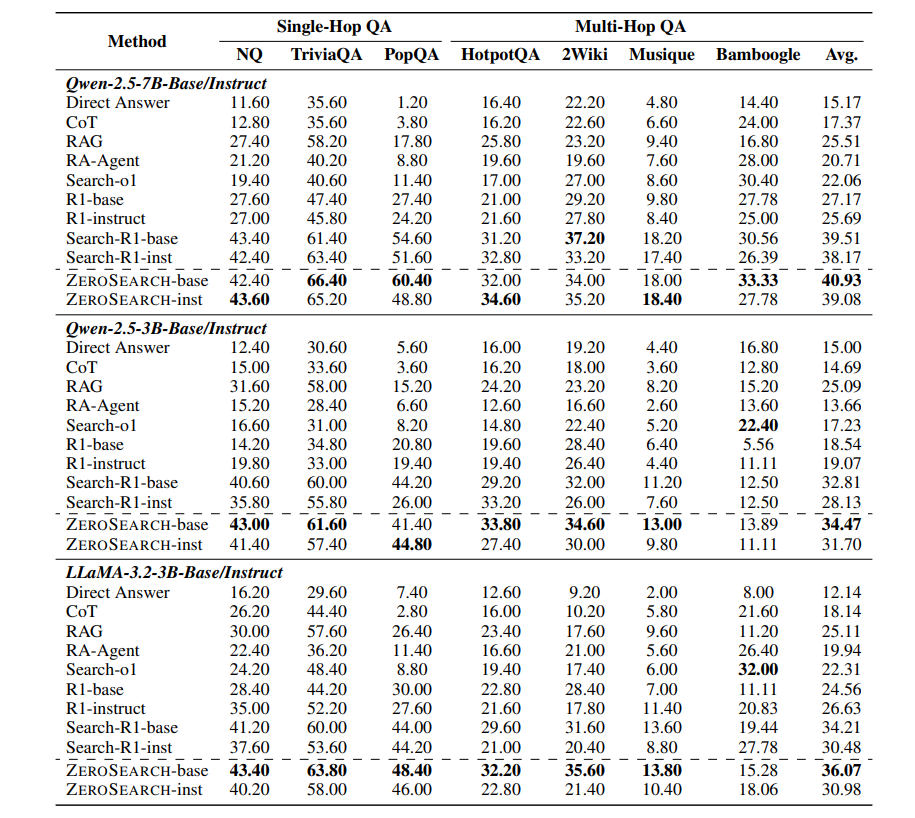
This innovation arrives as organizations increasingly seek cost-effective ways to implement advanced AI capabilities. By removing the need for constant search engine interactions during training, ZeroSearch could make sophisticated language model applications accessible to smaller research teams and businesses.
The technology's implications extend beyond immediate cost savings. Developers can now train models with more predictable performance characteristics, free from the variability of live web searches. As AI systems grow more complex, such efficient training paradigms may prove crucial for sustainable advancement in natural language processing.
Key Points
- Reduces LLM retrieval training costs by 88% through simulated search
- Eliminates dependency on unstable external search results
- Improves reasoning clarity with structured training templates
- Demonstrates superior performance in experimental evaluations
- Performance scales effectively with increasing model size