Yuan3.0Flash: The Open-Source AI Powerhouse That's Changing the Game
A New Contender in the AI Arena
The team at YuanLab.ai has thrown down the gauntlet with their latest release - Yuan3.0Flash, an open-source multimodal foundation model that's turning heads in the AI community. What makes this release special? It's not just another large language model - it's a carefully engineered solution that balances power with efficiency.
Smarter, Not Harder
At its core, Yuan3.0Flash boasts an impressive 40 billion parameters, but here's the clever part: it uses a sparse mixture-of-experts (MoE) architecture that only activates about 3.7 billion parameters during inference. This innovative approach means you get top-tier performance without the usual energy-guzzling drawbacks we've come to expect from large models.
"The 'less computing power, higher intelligence' concept isn't just marketing speak," explains Dr. Chen from YuanLab.ai. "We've built a system that knows when to bring its full strength to bear and when to conserve resources."
Under the Hood
The magic happens through three key components:
- A visual encoder that transforms images into tokens
- A language backbone with local filtering enhanced attention (LFA)
- A multimodal alignment module that helps these systems work together seamlessly
This architecture isn't just theoretical - it's delivering real-world results that are turning heads in enterprise settings.
Beating the Giants at Their Own Game
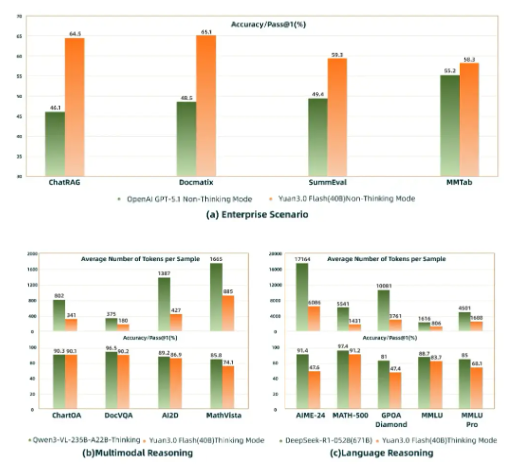
In head-to-head comparisons, Yuan3.0Flash has already surpassed GPT-5.1 in several critical business applications:
- ChatRAG (retrieval-augmented generation)
- Docmatix (multimodal document understanding)
- MMTab (table comprehension)
The model holds its own against much larger competitors too, matching the accuracy of models with up to 671 billion parameters while using just a quarter to half of their computational resources.
What This Means for Businesses
For companies eyeing AI solutions, these performance gains translate directly to cost savings. "We're seeing enterprises reduce their inference costs by 50-75% while maintaining or improving output quality," notes an early adopter from the financial sector.
The open-source nature of Yuan3.0Flash adds another layer of appeal, allowing organizations to tailor the model to their specific needs without vendor lock-in.
The Road Ahead
The YuanLab team isn't resting on their laurels. They've announced plans for Pro and Ultra versions scaling up to a staggering 1 trillion parameters, promising even greater capabilities for specialized applications.
As AI continues its rapid evolution, solutions like Yuan3.0Flash demonstrate that bigger isn't always better - smarter architecture and thoughtful design can deliver outsized results without requiring supercomputer-level resources.
Key Points:
- Open innovation: Complete with weights and technical documentation for community development
- Efficiency champion: MoE architecture delivers big performance with modest compute needs
- Enterprise-ready: Already outperforming GPT-5.1 in key business applications
- Cost-effective: Dramatically reduces operational expenses compared to larger models
- Future-proof: Planned expansions will address even more complex use cases