Yuan3.0Flash: A Game-Changer in Open-Source AI
Yuan3.0Flash Emerges as Open-Source AI Powerhouse
The AI world just got more interesting with the release of Yuan3.0Flash by YuanLab.ai. This isn't just another large language model - it's a carefully engineered multimodal system that could change how businesses implement AI solutions.
Smarter Design, Better Performance
What makes Yuan3.0Flash stand out? Its clever sparse mixture-of-experts (MoE) architecture activates only about 3.7B parameters during inference - less than 10% of its full 40B capacity. Imagine getting premium performance while paying economy-class prices for computing power.
The team didn't stop there. They've incorporated:
- RAPO training: A reinforcement learning method that keeps the model focused
- RIRM mechanism: Reduces unproductive "thinking" cycles
- LFA structure: Enhances attention accuracy without draining resources
Seeing and Understanding Like Never Before
The visual encoder transforms images into tokens that work seamlessly with text inputs, creating what might be the most efficient cross-modal alignment we've seen in open-source models.
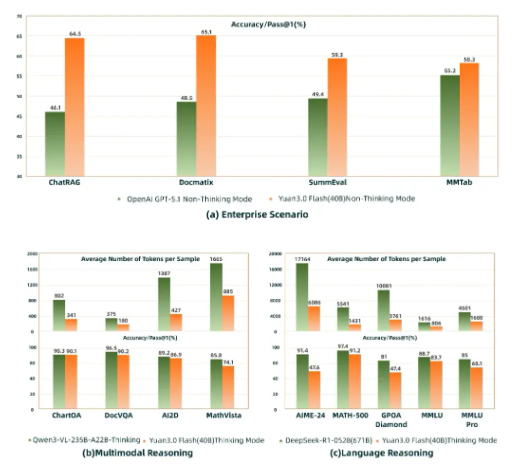
In head-to-head tests against GPT-5.1, Yuan3.0Flash shines particularly bright in:
- ChatRAG applications
- Multimodal document retrieval (Docmatix)
- Understanding complex tables (MMTab)
The numbers tell an impressive story - matching or exceeding larger models while using just a quarter to half of their token consumption.
What This Means for Businesses
For companies watching their AI budgets, Yuan3.0Flash could be the sweet spot between capability and cost-efficiency:
Performance comparable to models twice its size
Significantly lower operational expenses
The freedom to customize thanks to open-source availability
The roadmap looks equally promising with Pro (200B) and Ultra (1T) versions coming soon.
Key Points:
- Open innovation: Complete with weights and technical documentation for community development
- Efficiency breakthrough: MoE architecture delivers premium results without premium costs
- Enterprise-ready: Already outperforming GPT-5.1 in real-world business scenarios
- Future-proof: Larger versions planned to meet growing AI demands