Visual-ARFT: A Breakthrough in Multimodal AI Agents
Artificial intelligence continues to push boundaries in multimodal reasoning, with researchers now achieving significant progress in combining visual understanding with autonomous task execution. A collaborative team from Shanghai Jiao Tong University, Shanghai AI Lab, The Chinese University of Hong Kong, and Wuhan University has introduced Visual-ARFT (Vision Agent Reinforcement Fine-Tuning), a groundbreaking approach that transforms vision-language models into capable multimodal agents.
At its core, Visual-ARFT equips AI systems with what the researchers call "tool agent" capabilities. This means the technology doesn't just passively analyze images—it actively interacts with its environment. When faced with complex visual problems, these enhanced models can break down tasks into steps, search for information online, or even generate Python code to manipulate images directly.
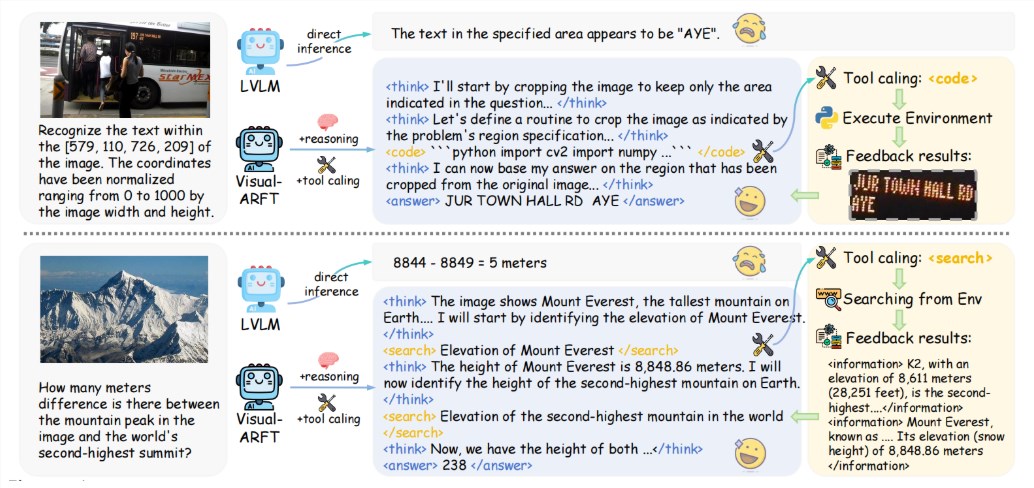
To measure the effectiveness of their innovation, the team created MAT-Bench (Multimodal Agent Tool Benchmark), a specialized testing environment featuring multi-step visual question answering challenges. The results surprised even the developers—models using Visual-ARFT consistently outperformed advanced systems like GPT-4o across several subtasks. This performance leap suggests we're entering new territory for AI's practical applications.
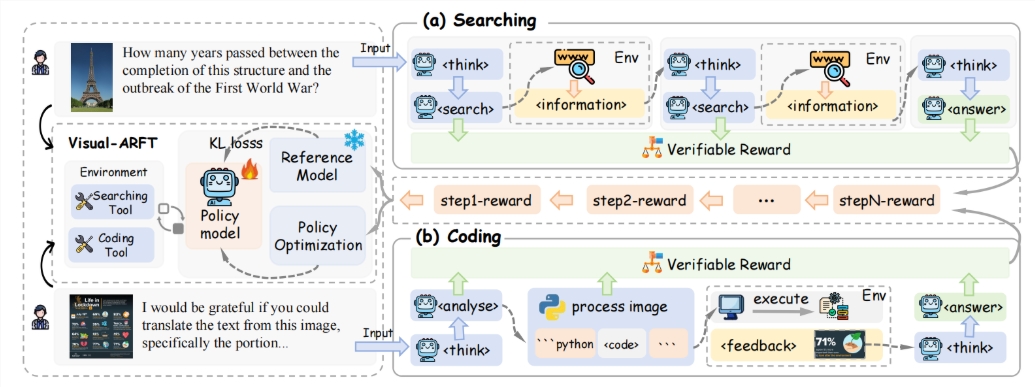
The secret lies in Visual-ARFT's training methodology. Rather than relying on massive datasets, the system uses reinforcement fine-tuning with an efficient reward mechanism. This approach teaches models not just what tools exist, but when and how to use them effectively. Imagine an AI that doesn't just recognize a graph in an image—it can pull relevant data from external sources to explain trends or anomalies.
What does this mean for real-world applications? The implications span from medical imaging analysis to automated content creation and beyond. As these multimodal agents become more sophisticated, they could revolutionize how we interact with visual information across industries.
The research team has made their work publicly available on GitHub: Visual-ARFT Project.
Key Points
- Visual-ARFT enables vision-language models to actively use external tools and execute complex tasks
- The method outperforms existing models like GPT-4o in specialized benchmark tests
- Reinforcement fine-tuning allows efficient training without massive datasets
- Potential applications range from medical imaging to automated content creation
- The technology represents a significant step toward practical multimodal AI agents