Unsloth AI's 1.8-bit Kimi K2 Model Cuts Costs by 80%
Unsloth AI Achieves Breakthrough with 1.8-bit Quantization
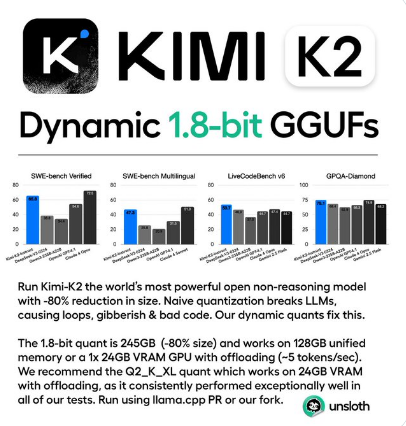
On July 14, Unsloth AI announced a significant advancement in model optimization by successfully quantizing Moonshot AI's Kimi K2 large language model (LLM) to 1.8-bit precision. This technological feat reduces the model's storage requirements from 1.1TB to just 245GB - an 80% reduction - while preserving all original performance benchmarks.
Technical Specifications and Performance
The Kimi K2 model, originally released on July 11, 2025, features:
- 1 trillion parameters (3.2 billion active)
- Mixture of Experts (MoE) architecture
- Specialization in code generation and reasoning tasks
Unsloth's dynamic quantization technology offers multiple versions from UD_IQ1 to UD-Q5_K_XL. Testing confirms the Q2_K_XL version (381GB) successfully completes complex tasks including:
- Generating functional game code (Flappy Bird)
- Passing advanced geometric reasoning tests (heptagon challenge)
The compressed model supports memory offloading, enabling operation on hardware as modest as:
- Apple M3 Ultra with 512GB RAM
- Multi-node NVIDIA B200 GPU clusters for production environments
Market Implications
This development positions Kimi K2 as a formidable competitor to proprietary models like:
- OpenAI's GPT-4.1
- Anthropic's Claude Opus 4
The cost reduction particularly benefits:
- Small and medium enterprises (SMEs)
- Independent developers/researchers
- Organizations requiring localized AI deployment
Commercial Note: Moonshot AI requires products with either:
- >100M monthly active users OR
- >$20M monthly revenue to display "Kimi K2" attribution in their UI.
Future Outlook
Industry analysts predict this advancement will accelerate adoption in:
- Education technology platforms
- Healthcare diagnostic systems
- Creative content generation tools The technology also establishes a new benchmark for efficient large model deployment.
Key Points:
- 80% storage reduction (1.1TB → 245GB)
- Maintains full performance capabilities
- Enables operation on consumer-grade hardware
- Opens commercial opportunities for SMEs
- Strengthens open-source AI ecosystem