UC Santa Cruz Launches OpenVision: A Versatile Open-Source Vision Encoder
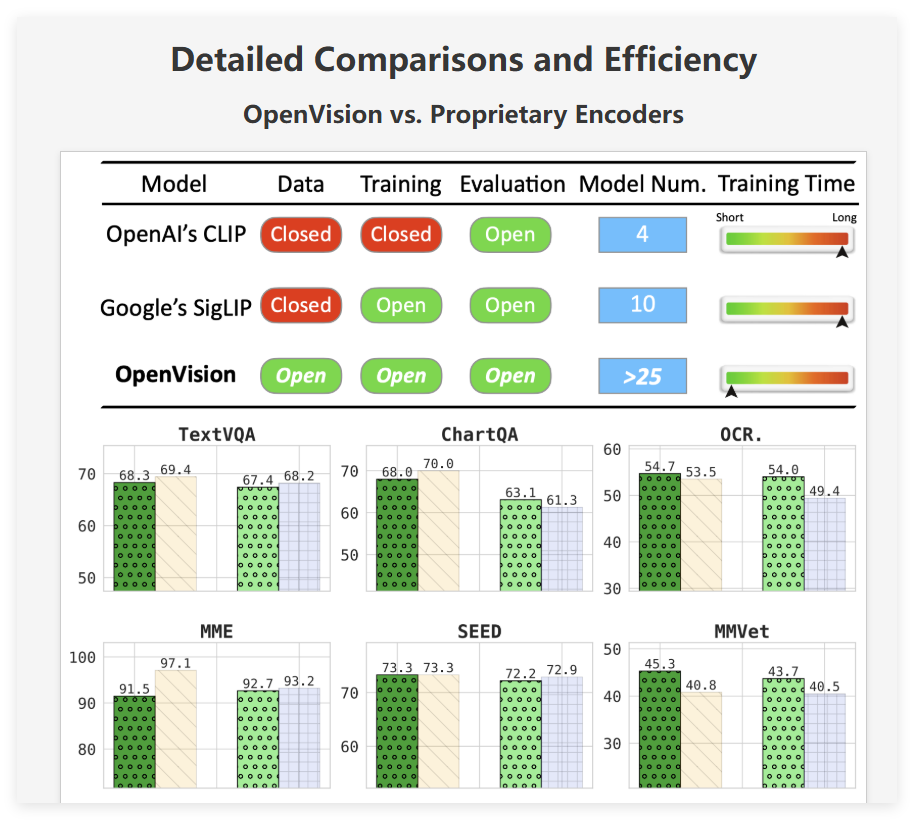
Researchers at UC Santa Cruz have introduced OpenVision, a groundbreaking series of open-source visual encoders designed to compete with established models like OpenAI's CLIP and Google's SigLIP. This release marks a significant advancement in multimodal AI systems, offering developers unprecedented flexibility in image processing applications.

Understanding Visual Encoders
These specialized AI models transform visual content into numerical representations that other systems can process. Acting as a crucial bridge between images and language models, they enable sophisticated analysis of visual elements including objects, colors, spatial relationships, and contextual meaning.
What Sets OpenVision Apart
Scalable Model Selection The framework offers 26 distinct models ranging from lightweight 5.9-million-parameter versions to robust 632-million-parameter configurations. This spectrum allows precise matching of computational resources to application needs—from construction site monitoring to appliance troubleshooting systems.
Adaptive Deployment Architecture OpenVision's design accommodates diverse operational environments. High-performance variants suit data center deployments where accuracy is paramount, while optimized smaller models enable efficient edge computing. The system's dynamic patch sizing (8×8 or 16×16) further allows resolution-computation tradeoffs.
Benchmark-Breaking Performance Initial evaluations demonstrate OpenVision's superiority across multiple vision-language tasks. While supporting traditional metrics like ImageNet scoring, the team advocates for broader evaluation protocols that better reflect real-world multimodal applications.
Innovative Training Methodology A progressive resolution approach accelerates training by beginning with low-resolution images before refining on higher-quality inputs. This technique achieves 2-3x faster training than comparable systems without compromising output quality.
Edge Computing Optimization In a notable demonstration, researchers paired OpenVision with a compact 1.5M-parameter language model to create a sub-2.5M multimodal system that maintains strong performance in visual Q&A and document analysis tasks—ideal for resource-constrained environments.
Enterprise Implications
The project's fully open-source nature gives organizations complete visibility into model architecture—a critical factor for security-conscious industries handling sensitive visual data. Available in PyTorch and JAX implementations via Hugging Face, OpenVision provides plug-and-play integration with existing AI workflows.
The research team has published comprehensive training recipes alongside model weights, enabling full transparency and customization opportunities for commercial implementations.
Key Points
- Open-source alternative to proprietary vision encoders like CLIP/SigLIP
- Offers 26 model variants from 5.9M to 632M parameters
- Features adaptive patch sizing and progressive training techniques
- Demonstrates strong performance in edge computing applications
- Fully transparent architecture supports enterprise security requirements