Tsinghua and Tencent Team Up for AI Breakthrough: 4.1x Faster MoE Inference
Chinese Research Team Outperforms Global Competitors in AI Efficiency Challenge
In a remarkable display of technical prowess, researchers from Tsinghua University's Storage Lab and Tencent's MegEngine AI Infra team have claimed victory at the MLSys2026 MoE Inference Challenge. Their groundbreaking work on optimizing mixture-of-experts models has set a new standard for AI efficiency.

Breaking Through the Bottleneck
Facing the formidable challenge of running trillion-parameter MoE architectures on specialized neural processing units (NPUs), the joint team developed a comprehensive optimization strategy. "We knew we had to rethink every aspect of the inference pipeline," explains Dr. Liang Chen, lead researcher from Tsinghua. "The traditional approaches simply weren't cutting it for these massive models."
Their solution? A multi-pronged approach that tackles the problem from multiple angles:
- E-Shard strategy: A clever partitioning method that splits computational tasks by expert modules
- PSUM 3D tensor readout: Optimizes how data moves through the processing pipeline
- GEMV path innovation: Enables parallel processing by scattering outputs across multiple Banks
- Scalar engine utilization: Reduces initial data transfer delays significantly
"What really sets this apart," notes Tencent's engineering lead Zhang Wei, "is how we've addressed the fundamental inefficiencies in data movement and activation transfers at the operator level."
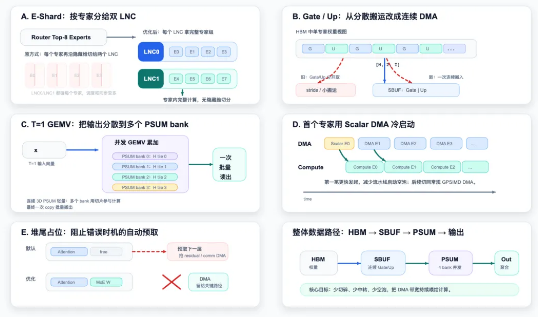
Figure 3: The team's MoE optimization architecture, showcasing their integrated approach to expert partitioning, data transfer, and parallel processing.
The 'Knight' in Shining Armor
The team's secret weapon came in the form of "Knight," an automated inference optimizer that uses an agent-based approach to explore optimization possibilities. This clever system creates proposals, implements code changes, and iterates improvements in a continuous loop.
The results speak for themselves:
- End-to-end inference time slashed from 14.91 seconds to just 3.56 seconds
- Single-step decoding delay reduced by more than half (12.63ms to 5.45ms)
- DMA engine utilization during weight loading boosted to ~80%
"Knight helped us explore optimization avenues we might have otherwise missed," Dr. Chen admits. "It's like having an extra team member who never sleeps."
Beating the Best
The Chinese team's achievement stands out even more considering the competition included research powerhouses like Stanford and MIT. "This wasn't just about raw performance," Zhang Wei emphasizes. "We focused on creating practical solutions that could be implemented in real-world systems."
Industry experts are already taking notice. "This work provides a blueprint for deploying massive MoE models efficiently," comments AI researcher Emma Johnson from Cambridge. "The 4.1x improvement isn't just impressive—it's potentially game-changing for applications that need real-time responses from trillion-parameter models."
Key Points
- Record Performance: 4.1x speedup in MoE model inference on NPU hardware
- Innovative Techniques: E-Shard partitioning, PSUM 3D tensor processing, GEMV path optimization
- Automation Advantage: "Knight" optimizer expands search space for potential improvements
- Practical Impact: Solution addresses real-world deployment challenges for massive AI models
- Global Recognition: Outperformed teams from top international universities at MLSys2026