Tongyi Lab Open-Sources VRAG-RL: A Breakthrough in Visual AI Reasoning
The Natural Language Intelligence Team at Tongyi Lab has unveiled VRAG-RL, an open-source multimodal reasoning framework designed to revolutionize how AI systems process visual information. This innovative solution tackles one of the most persistent challenges in artificial intelligence: extracting meaningful insights from visual data like images, tables, and design drafts.
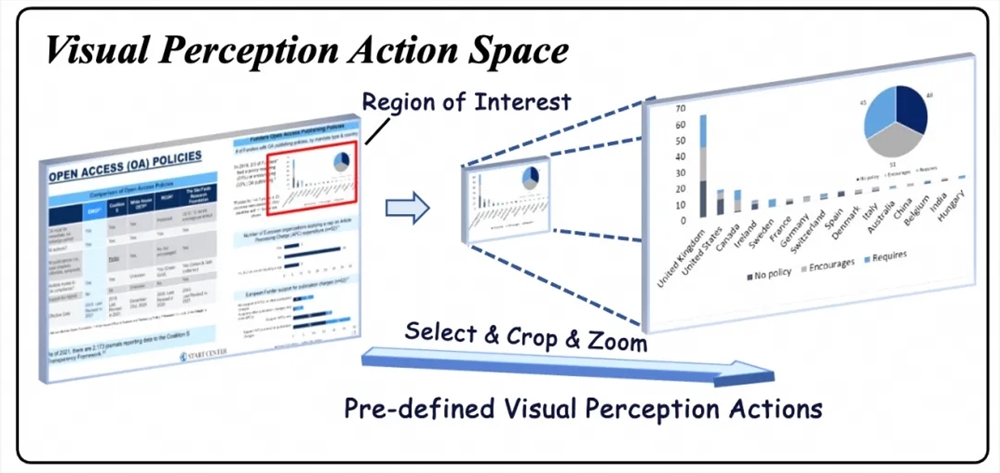
Traditional Retrieval-Augmented Generation (RAG) methods often stumble when faced with visually rich content. While they excel with text, these systems struggle to interpret charts, diagrams, or complex layouts effectively. VRAG-RL breaks through these limitations with a three-pronged approach combining reinforcement learning, visual perception mechanisms, and collaborative retrieval-reasoning optimization.
The framework introduces dynamic visual perception actions including region selection, cropping, and scaling operations. These capabilities allow the system to progressively focus on information-dense areas, moving from broad overviews to precise details. This granular approach not only boosts comprehension but dramatically improves retrieval efficiency—a critical factor for real-world applications.
What sets VRAG-RL apart is its training methodology. The system employs a multi-expert sampling strategy that blends the broad reasoning capabilities of large language models with the precision of specialized expert models. A sophisticated reward system evaluates performance across multiple dimensions including retrieval speed, pattern recognition accuracy, and output quality.
The team implemented cutting-edge GRPO algorithms during development, creating simulated search environments that eliminate costly API calls during training. This innovation allows for more extensive experimentation while maintaining budget efficiency—an important consideration for research teams and commercial applications alike.
Benchmark tests reveal VRAG-RL's superior performance across various visual language tasks. The framework handles everything from simple single-hop queries to complex multi-step reasoning problems involving charts and intricate layouts. Its flexibility shines whether using traditional prompting techniques or advanced reinforcement learning approaches.
Practical applications are already emerging. The system's multi-round interaction capability enables progressive refinement of visual focus areas during reasoning processes. As it iteratively hones in on critical information zones, VRAG-RL simultaneously optimizes both retrieval paths and reasoning strategies—a dual optimization that delivers both accuracy and speed.
The project is now available on GitHub (github.com/Alibaba-NLP/VRAG), inviting researchers and developers to explore its potential. This release marks a significant step forward in bridging the gap between textual and visual understanding in AI systems.
Key Points
- VRAG-RL introduces novel visual perception actions for precise information extraction
- The framework combines reinforcement learning with expert model insights for superior performance
- Advanced GRPO algorithms enable cost-effective training through simulated search environments
- Benchmarks show significant improvements over existing methods across multiple visual tasks
- Open-source availability encourages community development and practical applications