Tencent's X-Omni AI Model Breaks New Ground in Multimodal Generation
Tencent's X-Omni AI Model Sets New Standard for Multimodal Generation
Tencent's research team has developed X-Omni, a groundbreaking multimodal AI model that simultaneously processes text and image generation with unprecedented accuracy. The model addresses long-standing challenges in AI-generated imagery, particularly the accurate rendering of text within images.
Solving Text Rendering Challenges
Traditional AI image models have struggled with text generation accuracy, often producing spelling errors or distorted characters due to pixel-by-pixel generation methods. X-Omni's innovative approach combines:
- A reinforcement learning framework with multidimensional rewards
- Specialized evaluation tools including HPSv2 (aesthetic quality) and GOT-OCR2.0 (text recognition)
- Unified semantic representation through SigLIP-VQ tokenizer

Unified Architecture Breakthrough
Unlike conventional systems that separate image generation and understanding, X-Omni achieves:
- Single-model processing for both creation and interpretation
- High performance without classifier-free guidance (reducing computational overhead)
- Superior results in benchmarks against specialized models like LLaVA-One Vision
The model converts visual information into semantic tokens processable by language models, creating a seamless workflow between modalities.
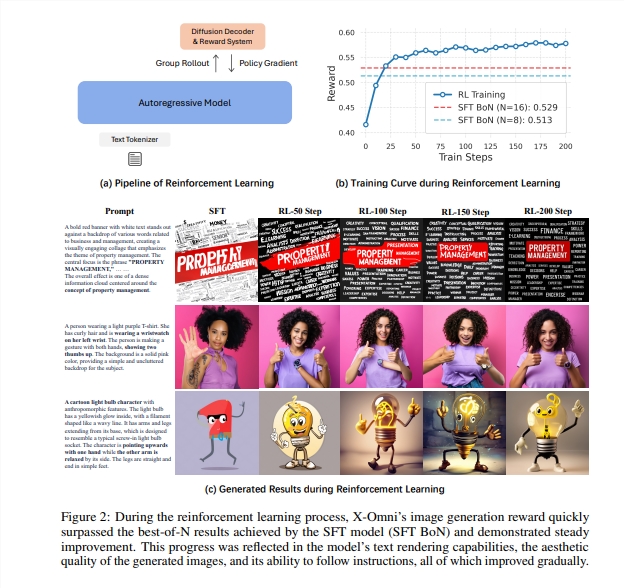
Benchmark Dominance
Testing reveals X-Omni's advantages:
| Metric | Performance |
|---|
The model maintains these results while using 30% less computational resources than comparable systems employing classifier-free guidance.
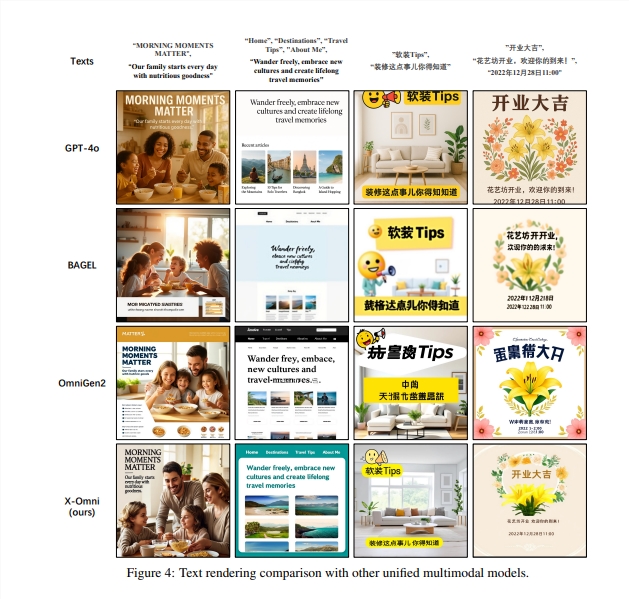
Future Implications
The success of X-Omni demonstrates:
- The viability of discrete autoregressive models for multimodal tasks
- Potential for more efficient AI-assisted content creation
- Foundation for next-generation unified AI systems
The technology could revolutionize fields from digital marketing to educational content development.
Key Points:
- First unified model handling both image generation/understanding at scale
- Solves persistent text-rendering accuracy issues in AI imagery
- Operates efficiently without classifier-free guidance
- Outperforms specialized competitors across multiple benchmarks
- Opens new possibilities for automated visual content creation