Tencent Launches Hunyuan-A13B Model API
Tencent Launches Hunyuan-A13B Model API
Tencent Cloud has officially launched the API service for its Hunyuan-A13B model, a groundbreaking 13B-level MoE (Mixture of Experts) open-source hybrid inference model. The pricing is set at 0.5 yuan per million Tokens for input and 2 yuan per million Tokens for output, making it an attractive option for developers.
Key Features of Hunyuan-A13B
The Hunyuan-A13B model is designed with a compact architecture, featuring a total parameter count of 80B but only 13B activated parameters. This design ensures performance comparable to leading open-source models while offering faster inference speeds and improved cost-effectiveness. The model is particularly strong in Agent tool calls and long text processing, making it versatile for various AI applications.
Agent Capabilities
To enhance Agent functionalities, the Tencent HuanYuan team developed a multi-Agent data synthesis framework. This framework integrates environments like MCP, sandbox, and large language model simulation, leveraging reinforcement learning to enable autonomous exploration and learning. This significantly boosts the model's practicality.
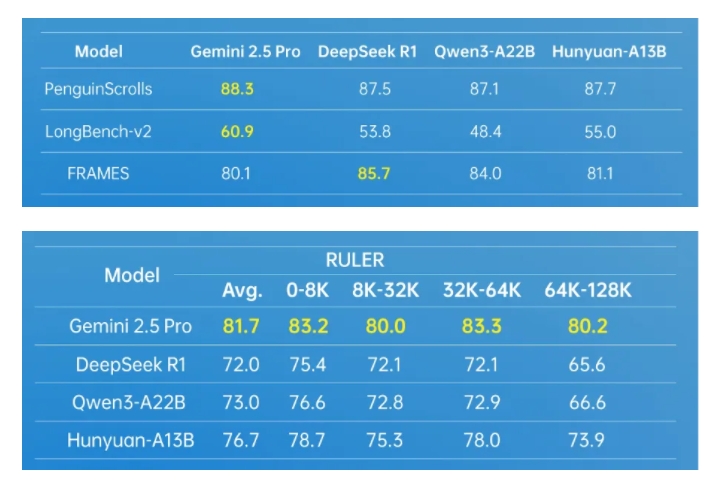
Long Text Processing
The Hunyuan-A13B supports a native context window of 256K and performs exceptionally well on multiple long text datasets. It also introduces a fused reasoning mode, allowing users to switch between fast and slow thinking modes based on task requirements. This ensures both efficiency and accuracy.
Developer-Friendly Design
For individual developers, the Hunyuan-A13B is highly accessible. It can be deployed with just one mid-range GPU card under strict conditions. The model is integrated into mainstream open-source inference frameworks and supports various quantization formats. Its throughput is more than twice that of cutting-edge open-source models, showcasing its performance and flexibility.
Innovative Training Approaches
The success of Hunyuan-A13B stems from Tencent's innovative pre-training and post-training techniques. During pre-training, the team used a corpus of up to 20T tokens, covering multiple fields to enhance general capabilities. They also developed a joint formula for the Scaling Law applicable to MoE architectures, providing quantitative engineering guidance. In the post-training phase, a multi-stage approach further refined the model's reasoning and generality.
Real-World Applications
The Hunyuan-A13B is one of the largest language models used internally at Tencent, applied in over 400 business scenarios with daily requests exceeding 130 million. This underscores its reliability and value in practical settings. For more details, visit Tencent Cloud.
Key Points:
- Competitive pricing: 0.5 yuan/million Tokens (input), 2 yuan/million Tokens (output).
- Compact design: 80B total parameters, 13B activated.
- Excels in Agent tool calls and long text processing (256K context window).
- Developer-friendly: Deployable with one mid-range GPU card.
- Widely used: Over 400 business scenarios, 130M daily requests.