Tencent Hunyuan Unveils Major AI Model Upgrades, Introduces T1-Vision and Voice Models
Tencent's AI research division, Hunyuan, has rolled out comprehensive upgrades to its model ecosystem, introducing two groundbreaking additions: the T1-Vision visual reasoning model and Hunyuan Voice communication model. These developments mark a significant leap forward in multi-modal AI capabilities.
The upgraded portfolio includes enhanced versions of existing models like Hunyuan TurboS, which now ranks among the top eight global models on the Chatbot Arena evaluation platform. According to Tao Dao生, Tencent's Senior Executive Vice President, TurboS demonstrates particularly strong performance in scientific and mathematical reasoning after implementing innovative pre-training techniques that improved these capabilities by over 10%.
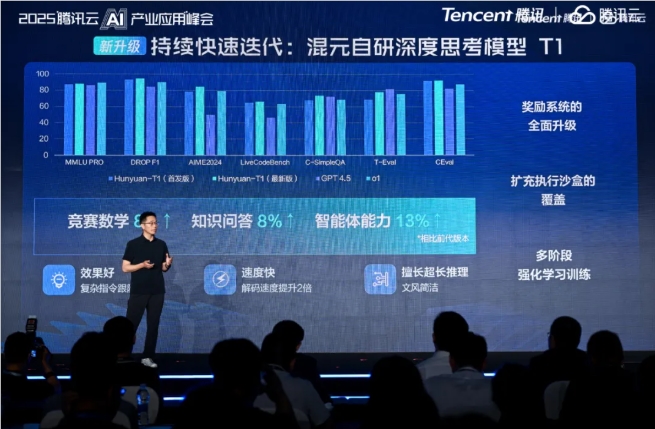
The T1 deep thinking model received substantial improvements as well. Its competition-level mathematics performance jumped 8%, while complex task handling saw a 13% boost. These enhancements reflect Tencent's focused investment in developing specialized AI competencies.
T1-Vision introduces original long-chain thinking architecture, supporting multi-image inputs for more efficient visual comprehension. Compared to previous solutions, it delivers 5.3% better overall performance with 50% faster understanding speed - crucial for applications requiring rapid image analysis.

For voice interactions, Hunyuan Voice cuts latency to just 1.6 seconds, achieving a 30% response speed improvement over previous versions. This advancement could transform real-time communication applications where lag creates friction.
Multi-modal generation sees parallel progress. Hunyuan 2.0 leads in accuracy and generation speed, while the 3D v2.5 model demonstrates superior controllability across generation categories. These improvements address growing demand for high-quality, real-time content creation tools.

Looking ahead, Tencent plans to introduce a large-scale 3D scene generation model capable of free roaming - a development that could revolutionize gaming and virtual environments. The company also reaffirmed its commitment to open-source initiatives, promising full-modal openness for images, videos, and 3D assets with free resources for partners.
Key Points
- Tencent launches T1-Vision for enhanced visual reasoning and Hunyuan Voice for low-latency communication
- Hunyuan TurboS now ranks among top eight global models with 10%+ scientific reasoning improvements
- Multi-modal generation capabilities see major upgrades across image, video and 3D models
- Future roadmap includes free-roaming 3D scene generation and expanded open-source offerings