Tencent AI Lab Develops Parallel-R1 Framework for Enhanced Reasoning
Tencent AI Lab Unveils Breakthrough Parallel Thinking Framework
With artificial intelligence rapidly evolving, researchers are increasingly focused on enhancing large language models' reasoning capabilities. Tencent AI Lab, collaborating with academic partners, has developed Parallel-R1, a novel reinforcement learning framework designed to teach AI systems parallel thinking—the ability to explore multiple solution paths simultaneously.
Addressing Limitations of Traditional Methods
Current approaches often rely on supervised fine-tuning (SFT), which presents significant drawbacks:
- Heavy dependence on high-quality training data
- Tendency toward imitation rather than autonomous reasoning
- Limited generalization capabilities

The Parallel-R1 framework introduces an innovative solution through:
- Simple prompt generation of parallel thinking data for basic math problems
- A progressive curriculum training model that builds complexity gradually
- Reinforcement learning techniques that foster genuine problem-solving abilities
Technical Innovations Behind Parallel-R1
The research team implemented several groundbreaking techniques:
Progressive Learning Approach
The model first masters parallel thinking syntax through elementary problems before advancing to complex mathematical challenges.
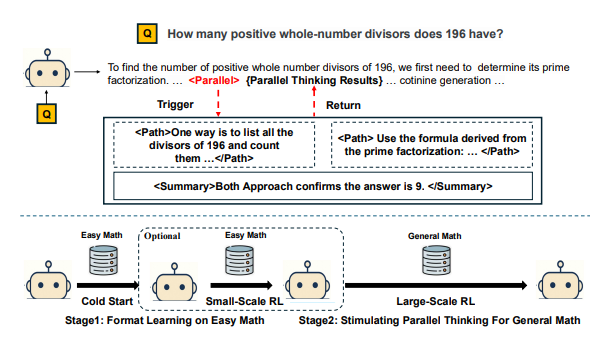
Dual Reward Strategy
The system employs an alternating reward mechanism balancing:
- Accuracy rewards for correct solutions
- Diversity rewards encouraging parallel path exploration This dual approach significantly enhances both precision and creative problem-solving.
Demonstrated Performance Improvements
Experimental results showcase remarkable advancements:
| Benchmark | Improvement |
|---|
The framework also demonstrates evolving reasoning strategies—transitioning from broad exploration early in training to precise verification methods post-training.
Future Implications
Parallel-R1's success opens new possibilities for:
- Enhanced complex problem-solving in AI systems
- Novel approaches to mathematical reasoning tasks
- Broader applications requiring multi-path analysis
The breakthrough highlights parallel thinking's potential as researchers continue pushing the boundaries of artificial intelligence capabilities.
Key Points:
- Tencent's Parallel-R1 enables simultaneous exploration of multiple reasoning paths
- Framework overcomes limitations of traditional supervised fine-tuning
- Progressive training and dual rewards drive significant performance gains
- Demonstrates up to 42.9% improvement on advanced math benchmarks
- Represents major advancement in AI reasoning methodologies