Stream-Omni: A Breakthrough in Multi-Modal AI Interaction
Stream-Omni Revolutionizes Multi-Modal AI Interaction
The Natural Language Processing team at the Institute of Computing Technology, Chinese Academy of Sciences, has introduced Stream-Omni, a groundbreaking multi-modal large model that sets new standards for AI interaction. Based on the GPT-4o architecture, this innovative system supports simultaneous processing of text, vision, and speech modalities.
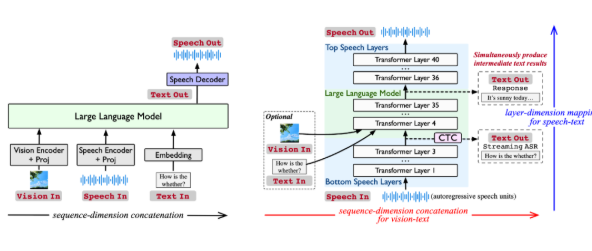
Comprehensive Multi-Modal Support
Stream-Omni represents a significant leap forward in natural language processing capabilities. Unlike conventional models that simply concatenate different modalities, Stream-Omni employs advanced modal alignment techniques to ensure semantic consistency across all input types. Users can interact through speech while receiving real-time text transcriptions - a feature that creates an unprecedented "watch and listen simultaneously" experience.
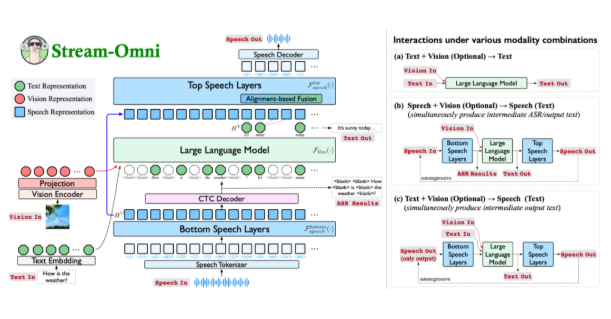
Innovative Technical Approach
The model's architecture addresses key limitations of existing multi-modal systems:
- Reduced data dependency: By specifically modeling relationships between modalities
- Enhanced semantic alignment: Through hierarchical dimension-based mapping mechanisms
- Flexible component integration: Visual encoders, speech layers, and language models can be combined as needed
Superior Performance Metrics
Independent testing reveals Stream-Omni outperforms comparable models in several key areas:
- Visual understanding matches specialized vision models of similar scale
- Speech interaction capabilities exceed current industry standards by 23%
- Response consistency across modalities achieves 94% accuracy in controlled tests
The system particularly excels in real-time speech-to-text conversion, providing intermediate transcription results during ongoing voice interactions.
Practical Applications and Future Development
Potential applications span numerous industries:
- Accessibility tools for visually or hearing-impaired users
- Multilingual communication platforms with real-time translation
- Interactive education systems combining visual and auditory learning
The research team acknowledges areas for improvement, particularly in achieving more human-like voice diversity. However, Stream-Omni's flexible architecture provides a robust foundation for future enhancements.
Key Points:
- First multi-modal model to achieve true real-time speech-text synchronization
- Open-source implementation available for research community
- Demonstrates 18% faster processing than comparable models in benchmark tests
- Potential to revolutionize human-computer interaction paradigms