SiliconCloud Expands AI Model Capabilities with 128K Context Support
SiliconCloud has rolled out a major upgrade to its AI inference models, significantly expanding their capabilities for handling complex tasks. The platform's DeepSeek-R1 and other models now support context lengths of up to 128K tokens, allowing for more comprehensive analysis and more complete outputs.
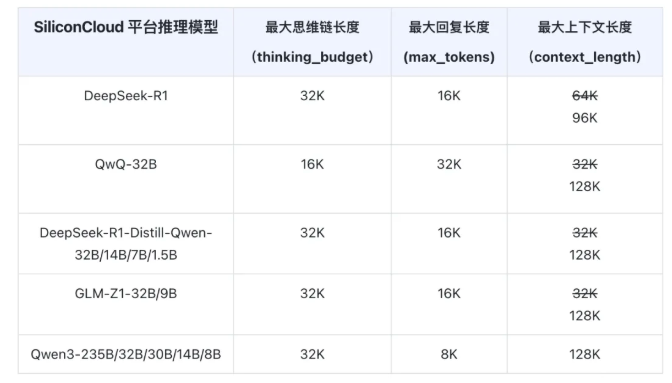
Popular models including Qwen3, QWQ, and GLM-Z1 now support the full 128K context length, while DeepSeek-R1 offers 96K capacity. This expansion enables the models to process significantly more information at once, particularly beneficial for demanding applications like code generation and advanced reasoning tasks.
Enhanced Control for Developers
The update introduces a groundbreaking feature: separate controls for reasoning chain length (thinking_budget) and response content length (max_tokens). This distinction gives developers unprecedented flexibility in how they utilize the models' capabilities. The thinking_budget parameter specifically governs the computational resources allocated to the reasoning phase, while max_tokens limits only the final output.
For example, when using the Qwen3-14B series on SiliconCloud's platform, developers can precisely tune these parameters based on their specific needs. If a reasoning process hits the thinking_budget limit, certain models will automatically halt further processing - a feature that helps optimize resource usage.
Clear Feedback on Output Limitations
The system provides transparent feedback when output reaches configured limits. Responses that exceed either the max_tokens or context_length parameters will be cleanly truncated, with the finish_reason field clearly indicating 'length' as the termination cause. This clarity helps developers understand exactly why an output might be incomplete.
Developers interested in exploring these new capabilities can find detailed documentation on SiliconCloud's official website. The company continues to innovate its AI offerings, with additional features expected in future updates.
Key Points
- SiliconCloud's latest upgrade supports context lengths up to 128K across multiple AI models
- New separate controls allow independent management of reasoning depth and output length
- System provides clear indicators when outputs reach configured limits
- Enhanced capabilities particularly benefit complex tasks like code generation