Shanghai AI Lab Takes on OpenAI with LLaMA-O1: The Ultimate Math Showdown
Shanghai AI Lab Takes on OpenAI with LLaMA-O1: The Ultimate Math Showdown
The open-source community just got a seismic upgrade! hanghai AI Labhas unleashed their version of OpenAI's Olympiad-crushing tool, LLaMA-O1. That's right, they’ve recreated the o1 project — and it’s open-source, baby! This isn’t just another AI toy; we’re talking Monte Carlo Tree Search, Self-Play reinforcement learning, and a brainy dual-strategy architecture straight from AlphaGo Zero. The AI scene is buzzing, and for good reason.

The Genius Behind the Madness
Before OpenAI even put out their o1 series, Shanghai AI Lab was already knee-deep in Monte Carlo Tree Search, looking to boost the mathematical prowess of large models. But once o1 dropped, they cranked it up a notch, focusing their laser beams on one thing: mathematical Olympiad problems. Their mission? To build an open-source rival to OpenAI's Strawberry project.
The squad used a clever pairwise optimization strategy to level up the LLaMA model. Instead of just slapping scores on answers, they compared the relative merits of two answers. And guess what? It paid off, big time! In the killer AIME2024 benchmark test, their optimized model nailed 8 out of 30 questions — while the original LLaMA-3.1-8B-Instruct limped in with only 2. The only things that could beat it? OpenAI’s closed-source o1-preview and o1-mini. ove over, corporate overlords!
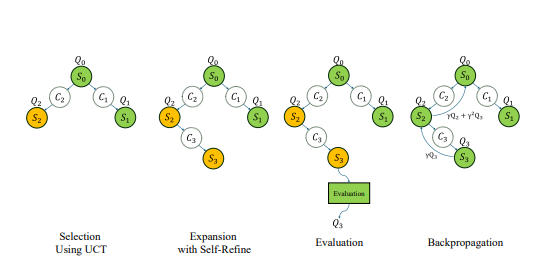
Cracking the Code: AlphaGo Zero Architecture
By the end of October, the Shanghai AI Lab team had some serious bragging rights. They managed to recreate OpenAI's o1, using the AlphaGo Zero playbook. Their model now flexes some next-level thinking, learning through interaction with a search tree — no need for manual labeling. And, in true open-source fashion, within a week, they flung the doors wide open for the world to see.
What’s inside this LLaMA-O1 treasure chest?
- Pre-training datasets
- Pre-trained models
- Reinforcement learning training code The dataset, dubbed OpenLongCoT-Pretrain, is a beast. It’s packed with over 100,000 long thought chains. Each one breaks down a full mathematical problem-solving process, from reasoning content to scoring results, problem descriptions, graphics, calculations — the whole nine yards. After soaking up this data, the model spits out complex thought chains like it’s nothing.
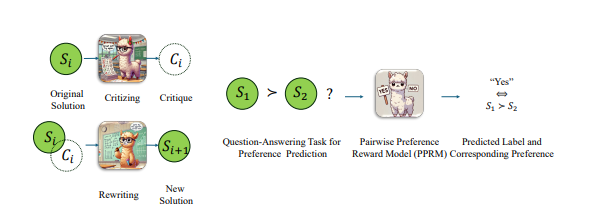
The Magic Behind LLaMA-O1
Despite its name, LLaMA-O1’s pre-trained model actually rides on Google’s Gemma2. Developers can then fire up the reinforcement learning engine. Here’s how the magic happens:
- Monte Carlo Tree Search handles self-play to generate experience.
- Experiences get stored in a prioritized replay buffer.
- Batches of data are pulled from the buffer for training.
- Model parameters and experience priorities are updated constantly. The process is supercharged with cutting-edge tech like LoRA for fine-tuning, PPO for policy optimization, and prioritized experience replay to make sure every second counts during training.
Who’s Behind the Curtain?
Here’s where it gets mysterious: the code for LLaMA-O1 is dropped under a GitHub account named SimpleBerry. No flashy descriptions. No tell-all profiles. Just a name and some serious code. From what we can dig up, it seems SimpleBerry is some kind of research lab, but their exact focus? Total mystery.
The Competition: Enter O1-Journey
LLaMA-O1 isn’t the only game in town. Shanghai Jiao Tong University is also in the race with their O1-Journey project. In early October, they dropped their first progress report, showcasing the Journey Learning paradigm — a slick combo of search and learning for solving math problems. The team is packed with undergrads and PhD students from the GAIR Lab, and they’re being mentored by some heavy hitters like Associate Professor Liu Pengfei and Sloan Prize winner Li Yuanzhi.
Want the full nerdy details? Check out their papers here and here.
Summary
- Shanghai AI Lab has open-sourced LLaMA-O1, a recreated version of OpenAI’s Olympiad tool.
- The project uses Monte Carlo Tree Search, self-play reinforcement learning, and the AlphaGo Zero architecture.
- The team made huge strides in solving mathematical Olympiad problems, outperforming most commercial solutions.
- The LLaMA-O1 model is trained on Google’s Gemma2 with advanced reinforcement learning techniques.
- There’s a rival project, O1-Journey, from Shanghai Jiao Tong University, which is also making waves in AI-powered math reasoning.