Robots Learn Like Humans: A Game-Changing Leap in AI Training
Robots Finally Learn the Way Humans Do
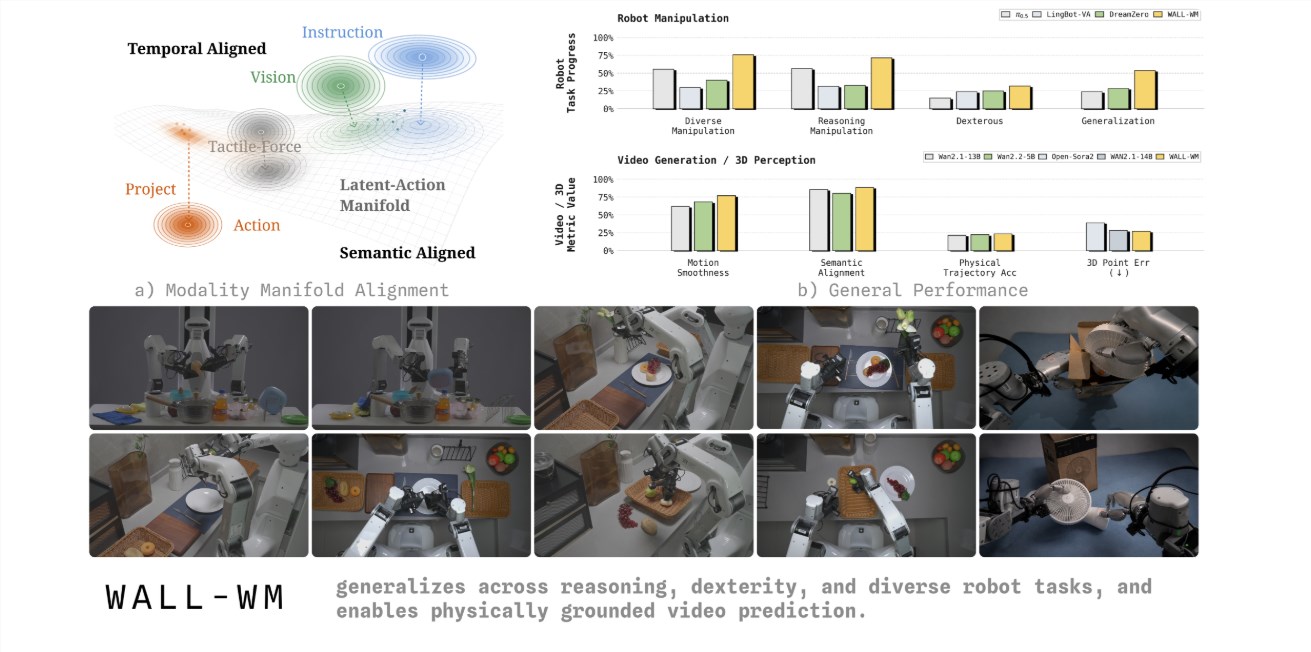
In what could mark a fundamental shift in artificial intelligence development, Variable Robot has introduced WALL-WM - the first embodied intelligence model that learns through semantic events rather than painstaking frame-by-frame analysis. This breakthrough, announced May 29, finally bridges the gap between how machines and humans understand tasks.

The Limits of Current Robot Learning
Today's robots typically learn through vision-language-action (VLA) models that predict fixed action blocks based on current images and instructions. It's like teaching a child to write by making them trace each letter stroke repeatedly without understanding what words mean. The results? Robots might perfectly execute practiced movements but fail completely when facing even slight variations - like trying to pick up a different shaped cup.
"Current methods force alignment where none naturally exists," explains the Variable team's research paper. "Text, vision, and action information operate on different time scales in reality."
Thinking in Events, Not Frames
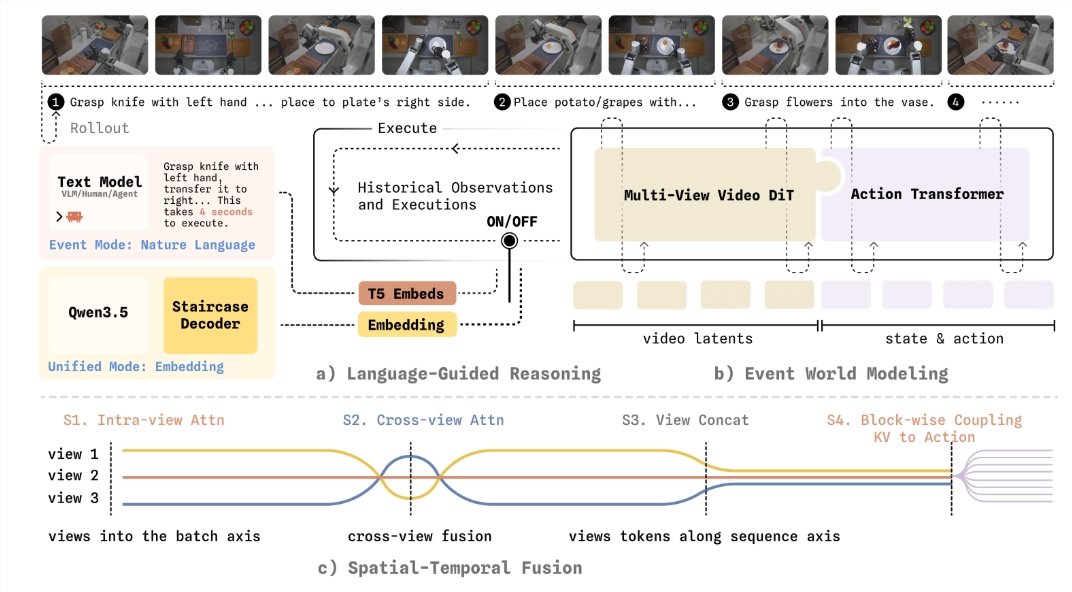
WALL-WM's revolutionary approach divides tasks into meaningful events - reach, grasp, move - much like how humans conceptualize actions. Instead of calculating the next robotic arm position, the model first simulates how the world will change after each event, then translates that prediction into motion.
Engineering Breakthroughs Behind the Scenes
Making this conceptual leap work required several technical innovations:
- Dual-mode flexibility: The same system can switch between event-based variable-length actions and traditional real-time control
- Protected learning: Critical visual dynamics from internet videos remain unbiased by action data
- 3D perception: Advanced masking techniques force true three-dimensional understanding across camera views
- Faster decisions: 'Stepped thinking chain decoding' reduces delays while keeping reasoning transparent
What This Means for Our Robotic Future
This event-based approach could finally enable robots to adapt to new situations as flexibly as humans do. Imagine a home assistant that can generalize from washing one dish to handling your entire china collection, or industrial robots that adjust seamlessly to production line changes.
Key Points:
- WALL-WM learns through semantic events rather than frame-by-frame analysis
- Solves critical generalization problems in current robotics
- Maintains dual operation modes for flexibility
- Incorporates multiple engineering innovations for real-world performance
- Potentially transforms how robots learn and adapt to new situations