Recurrent Models Breakthrough: 500 Steps to Handle Ultra-Long Sequences
Recurrent Models Achieve Breakthrough in Long-Sequence Processing
In the rapidly evolving field of deep learning, a significant advancement has emerged that could reshape how artificial intelligence systems handle extensive data sequences. Researchers from Carnegie Mellon University and Cartesia AI have developed an innovative approach that enables linear recurrent models to process exceptionally long sequences - up to 256,000 elements - with remarkable efficiency.
The Challenge of Long Sequences
Traditional Transformer models, while powerful for many applications, face inherent limitations when processing lengthy sequences. Their computational complexity grows quadratically with sequence length, creating practical constraints on context windows. Recurrent neural networks (RNNs) and newer linear recurrent models like Mamba offer an alternative approach but have historically underperformed on shorter sequences compared to Transformers.
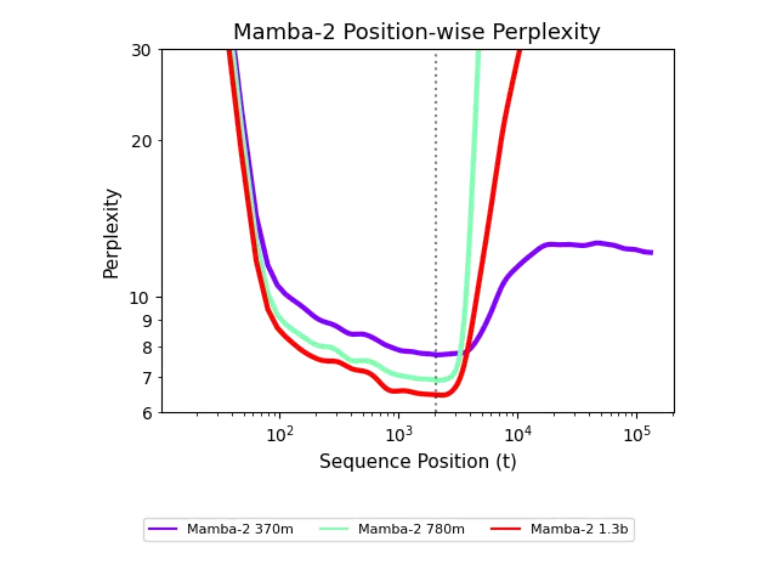
The Research Breakthrough
The research team discovered that with just 500 steps of targeted training intervention, recurrent models could achieve unprecedented generalization capabilities for ultra-long sequences. This finding challenges previous assumptions about the fundamental limitations of recurrent architectures.
Dr. Elena Rodriguez, lead researcher at Cartesia AI, explained: "Our work demonstrates that recurrent models don't have intrinsic flaws - we simply hadn't unlocked their full potential. With proper training techniques, they can match or exceed Transformer performance on long-sequence tasks while maintaining computational efficiency."
The Unexplored States Hypothesis
The team introduced a novel explanatory framework called the "Unexplored States Hypothesis", which posits that traditional training methods expose recurrent models to only a limited subset of possible state distributions. This limitation causes poor performance when encountering longer sequences during inference.
To address this, researchers developed several innovative training interventions:
- Random noise injection to expand state exploration
- Noise fitting techniques to maintain model stability
- State transfer methods to preserve learned patterns across sequence lengths
Practical Implications and Future Directions
The implications of this research extend across multiple AI application domains:
- Genomic analysis: Processing complete DNA sequences without fragmentation
- Financial forecasting: Analyzing years of market data in single passes
- Climate modeling: Handling decades of environmental sensor readings
- Document processing: Understanding book-length texts as continuous contexts
The research team has made their training protocols publicly available, encouraging further development in the field. Early adopters report significant improvements in both performance and energy efficiency compared to Transformer-based approaches for long-sequence tasks.
Key Points:
- Recurrent models can now process sequences up to 256k elements long
- Requires only 500 steps of specialized training intervention
- Challenges Transformer dominance in long-sequence applications
- Based on new "Unexplored States Hypothesis" framework
- Opens new possibilities for data-intensive AI applications