Qwen's CoGenAV Model Revolutionizes Speech Recognition with Audio-Visual Sync
The Tongyi Foundation Model has unveiled CoGenAV, a groundbreaking multimodal speech representation system that integrates audio and visual perception to overcome traditional voice recognition limitations. This innovation promises to transform how machines understand human speech, particularly in challenging acoustic environments.

Traditional voice recognition systems often struggle with background noise, but CoGenAV takes a novel approach by analyzing both sound waves and lip movements simultaneously. The model learns temporal relationships between audio signals, visual cues from mouth shapes, and text information to create a more robust framework for speech processing.
Technical Innovation At its core, CoGenAV employs a "Contrastive Generation Synchronization" strategy. The system uses ResNet3D CNN to analyze video footage of speakers' lips, capturing the dynamic relationship between mouth movements and sound production. Simultaneously, a Transformer encoder processes audio signals, precisely aligning these features with their visual counterparts.
The training process combines two powerful methods: contrastive synchronization enhances audio-video feature correspondence while filtering out irrelevant frames, and generative synchronization aligns multimodal features with their acoustic-text representations using pre-trained ASR models.
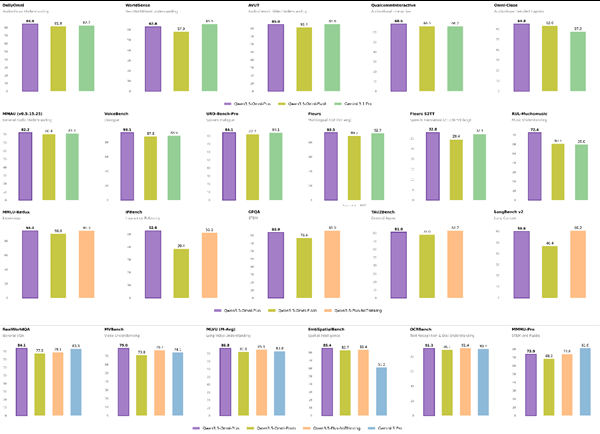
Benchmark-Breaking Performance CoGenAV has demonstrated remarkable results across multiple speech processing tasks:
- Achieved 20.5% Word Error Rate (WER) on LRS2 dataset for Visual Speech Recognition (VSR) using just 223 training hours
- Reached 1.27% WER for Audio-Visual Speech Recognition (AVSR) when combined with Whisper Medium
- Improved noise resistance by over 80% in 0dB environments compared to audio-only models
- Surpassed competitors in speech enhancement/separation tasks with SDRi metrics of 16.0dB (separation) and 9.0dB (enhancement)
- Set new standards for Active Speaker Detection with 96.3% mAP on Talkies dataset
Practical Advantages What makes CoGenAV particularly valuable is its seamless integration capability. The model can enhance existing voice recognition systems like Whisper without requiring modifications or fine-tuning. Its exceptional noise resistance and data efficiency also translate to significant cost savings in training and deployment.
The research team has made CoGenAV widely accessible through open-source platforms including GitHub, arXiv, HuggingFace, and ModelScope, inviting broader collaboration in the speech technology community.
Key Points
- CoGenAV synchronizes audio and visual data for superior speech recognition in noisy conditions
- The model combines contrastive and generative synchronization techniques for precise feature alignment
- Achieves state-of-the-art results across VSR, AVSR, speech enhancement/separation tasks
- Requires significantly less training data than conventional models while delivering better performance
- Open-source availability accelerates adoption and further development in the field