Peking University Unveils LLaVA-o1: A New Multimodal AI Model
Peking University Unveils LLaVA-o1: A New Multimodal AI Model
Recently, a research team from Peking University announced the launch of LLaVA-o1, a multimodal open-source model that claims to be the first visual language model capable of both spontaneous and systematic reasoning, similar to GPT-o1.
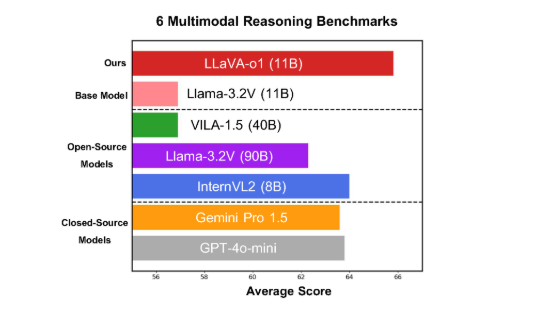
The model has demonstrated exceptional performance across six challenging multimodal benchmark tests. Its version with 11 billion parameters has outperformed notable competitors, including Gemini-1.5-pro, GPT-4o-mini, and Llama-3.2-90B-Vision-Instruct.
Features and Capabilities
LLaVA-o1 is built on the Llama-3.2-Vision model and employs a unique "slow thinking" reasoning mechanism. This allows it to engage in more intricate reasoning processes autonomously, a significant advancement over traditional chain-of-thought prompting methods.
In multimodal reasoning benchmark evaluations, LLaVA-o1 outperformed its base model by 8.9%. The model's reasoning process is structured into four distinct stages: summarization, visual interpretation, logical reasoning, and conclusion generation. Traditional models often exhibit a relatively simplistic reasoning process, which can lead to incorrect conclusions. In contrast, LLaVA-o1's multi-step reasoning framework enhances the accuracy of its outputs.
For example, when addressing the question, "How many objects are left after removing all the small bright balls and purple objects?", LLaVA-o1 begins by summarizing the question, extracting relevant information from the accompanying image, and then conducting a detailed, step-by-step reasoning process to arrive at the correct answer. This phased approach significantly bolsters the model's systematic reasoning capabilities, increasing its efficiency in tackling complex problems.
Innovation in Reasoning
Notably, LLaVA-o1 integrates a stage-wise beam search method throughout its reasoning phases. This innovative approach enables the model to generate multiple candidate answers at each stage of reasoning and select the optimal response to progress to the next stage, markedly enhancing the overall quality of its reasoning. Through methodical fine-tuning and the use of appropriate training data, LLaVA-o1 has shown remarkable performance compared to larger or closed-source models.
The research accomplishments of the Peking University team are poised to advance the field of multimodal artificial intelligence. They introduce fresh ideas and methodologies for future visual language understanding models. The team has pledged to fully open-source the code, pre-trained weights, and datasets associated with LLaVA-o1, encouraging further exploration and application by researchers and developers in the AI community.
For more detailed information, the research paper is available here, and the project's source code can be found on GitHub.
Key Points
- LLaVA-o1 is a new multimodal reasoning model released by teams from Peking University, featuring "slow thinking" reasoning capabilities.
- This model outperforms its base model by 8.9% in multimodal reasoning benchmark tests.
- LLaVA-o1 ensures accuracy through structured multi-step reasoning and will be open-sourced soon.