Open-Source Model Step-Audio-AQAA Revolutionizes Speech Generation
Open-Source Model Step-Audio-AQAA Revolutionizes Speech Generation
In the rapidly evolving field of artificial intelligence, voice interaction has emerged as a critical research area. Traditional large language models (LLMs) primarily focus on text processing, limiting their ability to generate natural speech and hindering seamless human-computer audio interaction.
To address this gap, the Step-Audio team has open-sourced Step-Audio-AQAA, an innovative end-to-end speech model. This breakthrough enables direct generation of natural, fluent speech from raw audio input, significantly enhancing the fluidity of human-computer communication.
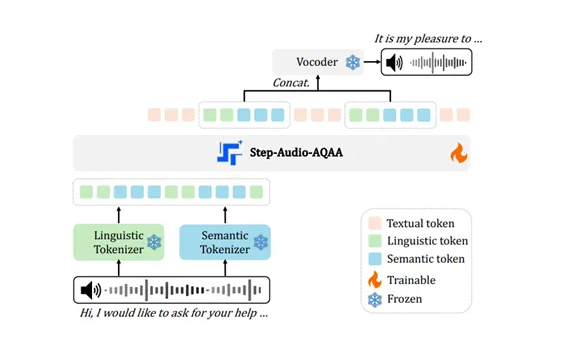
Architecture and Functionality
The model's architecture comprises three core modules:
- Dual-codebook audio tokenizer: Converts audio signals into structured token sequences using separate language and semantic tokenizers. The former extracts linguistic features, while the latter captures paralinguistic elements like emotion and tone.
- Backbone LLM (Step-Omni): A pre-trained multimodal model with 130 billion parameters capable of processing text, speech, and images. Its decoder architecture efficiently processes token sequences for subsequent speech generation.
- Neural vocoder: Synthesizes high-quality speech waveforms from discrete audio tokens using a U-Net architecture, ensuring processing efficiency and accuracy.
Impact and Availability
This development represents a major leap in human-computer audio interaction. By open-sourcing Step-Audio-AQAA, the team provides researchers with a powerful tool while laying groundwork for future intelligent voice applications.
The model is available at: https://huggingface.co/stepfun-ai/Step-Audio-AQAA
Key Points:
- Direct speech generation: Step-Audio-AQAA creates natural speech from audio input, improving interaction quality
- Advanced architecture: Three-module design effectively captures complex speech information
- Open-source availability: Enables broader research and development in voice technology
- Multimodal capability: Backbone LLM processes multiple data types for comprehensive understanding