Omni-R1 AI Model Breaks Records in Audio Q&A with Text-Driven Learning
A collaborative research team from MIT CSAIL, the University of Göttingen, and IBM Research has unveiled Omni-R1, a groundbreaking audio question-answering model that redefines performance standards in multimodal AI. Built upon the Qwen2.5-Omni framework, this innovation demonstrates how text reasoning can dramatically improve audio processing capabilities.
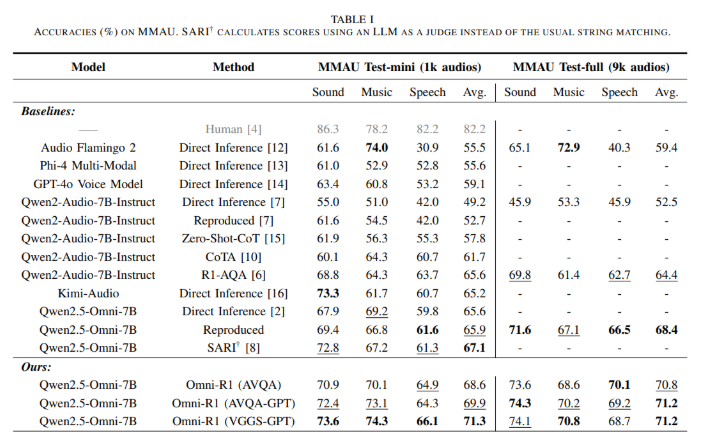
In benchmark testing, Omni-R1 achieved state-of-the-art results on the MMAU evaluation, covering diverse audio categories including speech, music, and environmental sounds. What surprised researchers most was discovering that text capability enhancements—not just audio optimizations—drove these improvements. Even when fine-tuned exclusively with text data, the model showed significant performance gains.
The team employed an innovative approach using ChatGPT-generated datasets—AVQA-GPT (40,000 entries) and VGGS-GPT (182,000 entries)—to train the model. These carefully curated datasets helped Omni-R1 outperform previous benchmarks by achieving an average score of 71.3%, surpassing earlier models like SARI.
At the heart of this advancement lies GRPO (Group Relative Policy Optimization), a memory-efficient reinforcement learning method that runs effectively on 48GB GPUs. Unlike traditional approaches requiring complex value functions, GRPO compares grouped outputs based on answer correctness to provide rewards. Researchers further enhanced training by expanding Qwen-2Audio's descriptions, boosting multimodal task performance.
"What makes Omni-R1 special isn't just its technical achievements," explains one researcher. "It challenges assumptions about how text and audio processing interact in AI systems." The model demonstrates that robust text understanding can compensate for limitations in pure audio analysis.
The team plans to release all resources publicly, inviting broader research collaboration. As AI systems increasingly handle real-world auditory environments—from smart assistants to medical diagnostics—Omni-R1's balanced approach could shape future developments.
Key Points
- Omni-R1 sets new benchmarks in audio Q&A through enhanced text reasoning capabilities
- The model leverages ChatGPT-generated datasets containing over 220k audio samples
- GRPO optimization enables efficient training on standard GPUs
- Text-only fine-tuning produces nearly comparable results to full audio training
- Researchers will release all datasets and methodologies for public use