NVIDIA Unveils NVILA: A Breakthrough Vision Language Model
NVIDIA has recently unveiled NVILA, a state-of-the-art vision language model designed to set new standards in visual AI technology. The new model promises significant advancements in both performance and efficiency, with improvements in training cost, memory usage, and processing speed.
Key Performance Enhancements
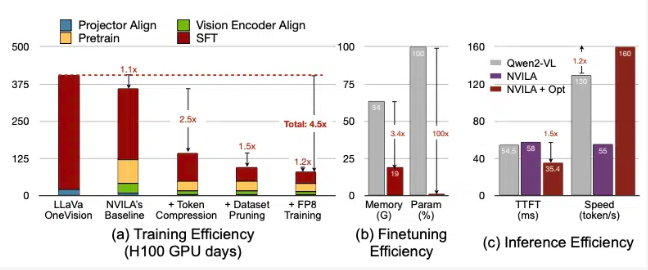
NVILA has been optimized to drastically reduce training costs, making it a more cost-effective solution compared to previous models. According to NVIDIA, the model reduces training expenses by 4.5 times, the memory required for fine-tuning decreases by 3.4 times, and the latency for pre-filling and decoding is almost cut in half. These improvements were observed in comparisons with LLaVa OneVision, a leading visual AI model in the industry.
Benchmark Results and Comparison
In a series of video benchmark tests, NVILA surpassed several major competitors, including GPT-4o Mini, and demonstrated strong performance against models like GPT-4o, Sonnet3.5, and Gemini1.5Pro. Notably, NVILA edged out Llama 3.2 in some aspects, showcasing its superior capabilities in real-world applications.
While NVIDIA has not yet released the model on the Hugging Face platform, the company has committed to making the code and model publicly available soon. This will help foster the model's reproducibility and encourage further research in the field.
Addressing High Training Costs
Training visual language models typically requires substantial computational resources. For instance, training a 7B parameter model can take up to 400 GPU days, and fine-tuning such a model demands more than 64GB of GPU memory. NVIDIA aims to mitigate these challenges by leveraging a unique technique called "expand then compress."
This method balances accuracy and efficiency, ensuring that the model performs well without compromising on the quality of input data. NVILA processes high-resolution images and video frames without reducing their size, thus preserving all the critical details.
Compression Techniques and Efficiency Gains
During the compression phase, NVILA reduces input data by converting visual information into fewer tokens and grouping pixels to retain essential details. NVIDIA's research also shows that doubling the resolution would normally double the number of visual tokens, leading to a significant increase in training and inference costs. To counteract this, NVILA compresses spatial and time tokens, ultimately reducing the overall cost of computation.
Additional Features and Future Development
In addition to these advancements, NVILA also includes several cutting-edge technologies, such as dynamic S2 expansion, DeltaLoss-based dataset pruning, and quantization using FP8 precision. These innovations further enhance the model's ability to efficiently process visual data.
NVIDIA demonstrated the model's capacity to answer multiple queries based on a single image or video, showcasing its versatility and ability to handle complex visual data. Compared to NVIDIA's earlier VILA1.5 model, NVILA showed notable improvements in both accuracy and efficiency.
The model's performance and additional details can be explored further in NVIDIA's published paper, which is available on Arxiv.
Paper link: https://arxiv.org/pdf/2412.04468
Key Points
- NVILA reduces training costs by 4.5 times, enhancing the efficiency of visual AI.
- The model maintains input data integrity by using high-resolution images and video frames.
- NVIDIA plans to release the code and model soon to support reproducibility and further research.