NVIDIA, MIT Unveil Fast-dLLM: 27x Faster AI Inference
In a significant leap for artificial intelligence, NVIDIA has partnered with MIT and the University of Hong Kong to introduce Fast-dLLM, a cutting-edge framework that dramatically enhances the performance of diffusion-based language models. The new technology achieves up to 27.6 times faster inference speeds while preserving model accuracy—a breakthrough that could reshape how we deploy AI systems.
The Challenge with Current Models
Diffusion models have long been considered promising alternatives to traditional autoregressive models due to their bidirectional attention mechanisms. These capabilities theoretically allow simultaneous generation of multiple tokens, potentially speeding up processing. However, real-world applications often reveal critical limitations:
- Computational redundancy: Each generation requires full attention state calculations
- Token dependency issues: Multi-token decoding can disrupt relationships between elements
- Quality compromises: Speed gains frequently come at the cost of output accuracy
The Fast-dLLM Solution
The research team addressed these challenges through two innovative approaches:
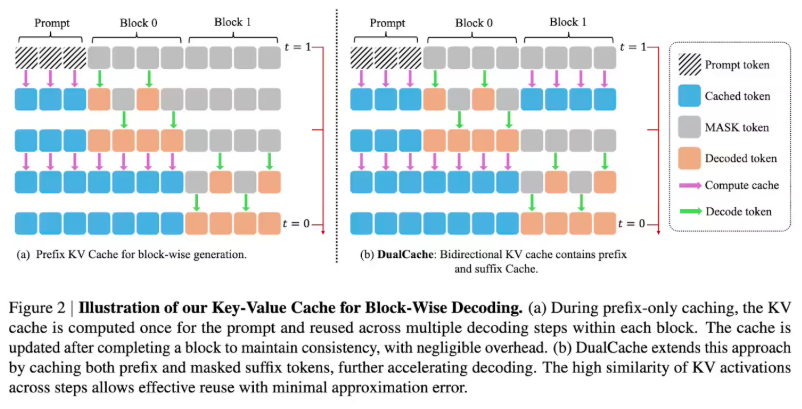
- Block-wise approximate KV caching: This mechanism divides sequences into blocks, precomputing and storing activation values to minimize redundant calculations. The DualCache variant further optimizes performance by leveraging similarities between adjacent inference steps.
- Confidence-aware parallel decoding: By selectively processing high-confidence tokens based on predefined thresholds, the system avoids potential conflicts in synchronous sampling while maintaining content quality.
Performance Breakthroughs
Benchmark tests demonstrate Fast-dLLM's remarkable capabilities:
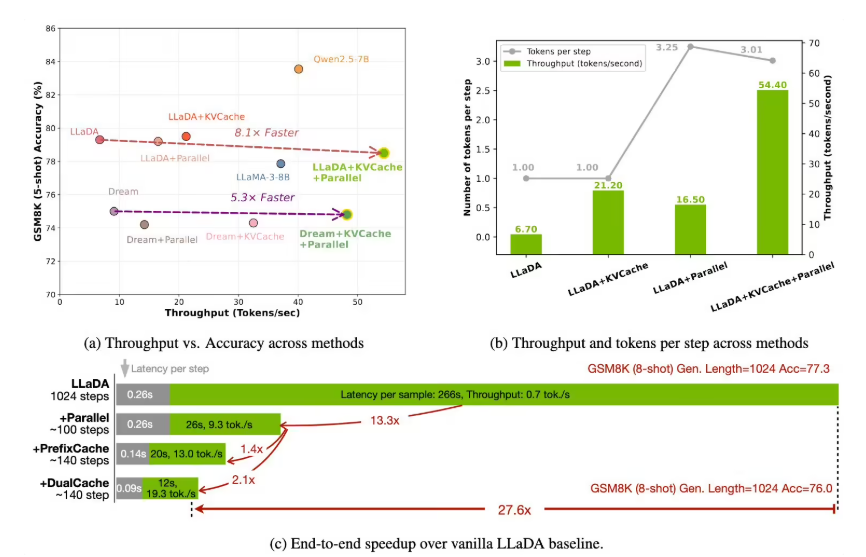
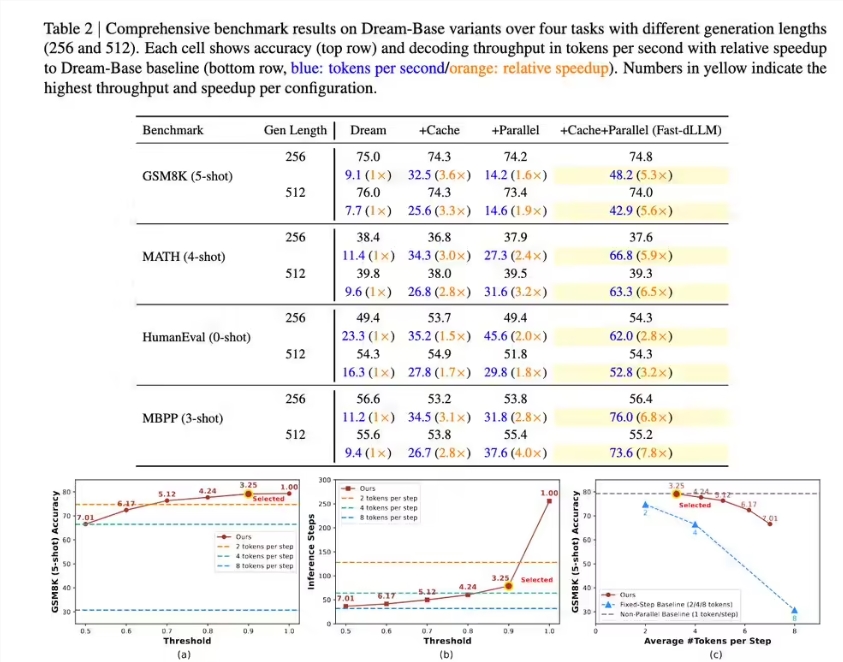
- GSM8K dataset: 27.6x speedup generating 1024 tokens (76% accuracy)
- MATH benchmark: 6.5x acceleration (39.3% accuracy)
- HumanEval/MBPP tests: 3.2x and 7.8x speed boosts respectively (54.3% accuracy)
The framework maintains this performance with only a 1-2 percentage point drop in accuracy—a negligible tradeoff for such substantial speed improvements.
Implications for AI Development
This advancement bridges the gap between diffusion models and their autoregressive counterparts in practical applications. By solving critical speed and quality challenges, Fast-dLLM opens new possibilities for:
- Real-time AI assistants
- Large-scale content generation systems
- High-performance computing applications
The technology could soon become foundational for next-generation language models across industries.
Key Points
- Fast-dLLM achieves up to 27x faster inference for diffusion-based language models
- Innovative caching and decoding strategies solve traditional bottlenecks
- Maintains near-baseline accuracy with minimal performance tradeoffs
- Positions diffusion models as viable alternatives to autoregressive approaches