Microsoft's Phi-4-mini Boosts Efficiency 10x for Laptops
Microsoft Unveils High-Efficiency Phi-4-mini Model
Microsoft has open-sourced Phi-4-mini-flash-reasoning, the latest addition to its Phi-4 family of AI models. This compact yet powerful version delivers 10x faster inference speeds compared to its predecessor while being optimized for devices with limited computing resources.

Performance Breakthroughs
The new model demonstrates:
- 2-3x reduction in average latency
- Exceptional performance in mathematical reasoning tasks
- Compatibility with single GPU setups, making it ideal for laptops and tablets
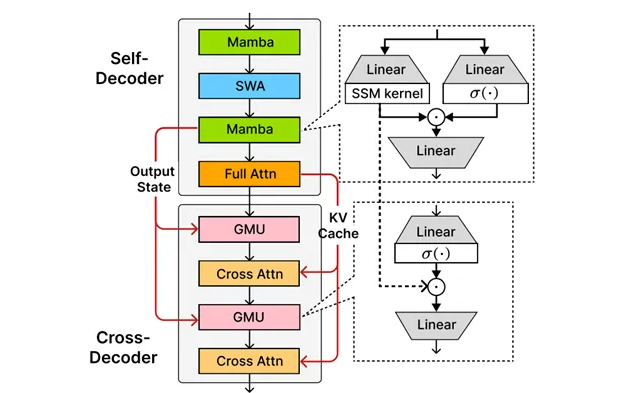
The SambaY Architecture Advantage
At the core of this release is Microsoft's proprietary SambaY architecture, developed in collaboration with Stanford University. This innovative decoder hybrid introduces:
- Gated memory units for efficient cross-layer memory sharing
- Linear pre-fill time complexity maintenance
- Enhanced long-context performance without positional encoding requirements
Benchmark Dominance
In rigorous testing, Phi-4-mini-flash-reasoning achieved:
- 78.13% accuracy on the 32K-length Phonebook task
- 10x higher decoding throughput than traditional models in 32K generation tasks
- Superior performance in complex mathematical problem-solving scenarios
The model was trained on a massive 5T token dataset using Microsoft's 3.8B parameter Phi-4-mini-Flash framework, overcoming training challenges through advanced techniques like label smoothing and attention dropout.
Availability:
- Open-source: Hugging Face
- NVIDIA API: NVIDIA Build
Key Points
🌟 10x efficiency boost makes AI accessible on consumer laptops
🔍 SambaY architecture revolutionizes memory sharing for better performance
📈 Benchmark leader with 78% accuracy in long-context tasks