Meta Unveils Breakthrough AI Model for Spatial Understanding
Tech giant Meta has partnered with researchers from The Chinese University of Hong Kong to introduce Multi-SpatialMLLM, a groundbreaking advancement in multimodal large language models (MLLMs). This new model addresses critical challenges in spatial understanding that have limited AI systems in fields like robotics and autonomous driving.
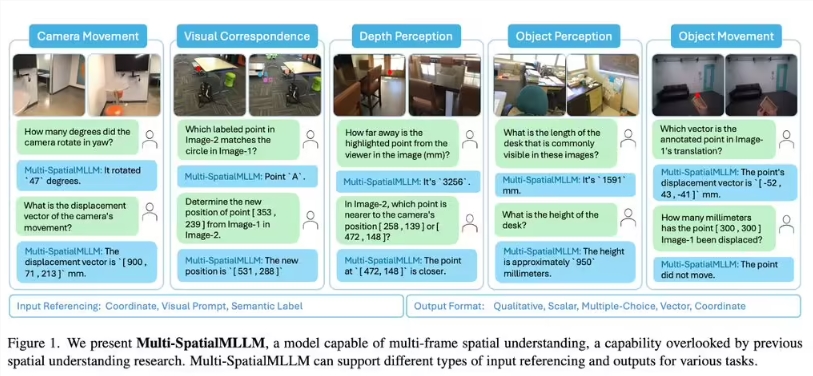
Traditional MLLMs have struggled with basic spatial tasks—sometimes failing to distinguish simple concepts like left from right. These limitations stem from reliance on static image analysis and insufficient training data. Multi-SpatialMLLM changes the game by combining three innovative components: depth perception, visual correspondence, and dynamic perception.
To train their model, the research team created the MultiSPA dataset—an extensive collection of over 27 million samples across diverse 3D and 4D environments. This dataset incorporates high-quality annotations from Aria Digital Twin and Panoptic Studio, along with task templates generated by GPT-4o.
The team designed five specialized training tasks to enhance spatial reasoning:
- Depth perception
- Camera movement detection
- Object size estimation
- Spatial relationship understanding
- Dynamic scene analysis
Initial results are impressive. Multi-SpatialMLLM shows a 36% average improvement on benchmark tests compared to existing models. It achieves 80-90% accuracy in qualitative spatial tasks—nearly doubling baseline performance. Even in challenging scenarios like predicting camera movements, it reaches 18% accuracy where previous systems failed completely.
On the BLINK benchmark for visual reasoning, the model scores nearly 90% accuracy, outperforming proprietary systems by 26.4%. Importantly, it maintains strong performance on standard visual question-answering tests, proving its versatility beyond spatial applications.
What does this mean for AI development? As industries demand more sophisticated visual understanding—from warehouse robots navigating complex environments to self-driving cars interpreting dynamic scenes—Multi-SpatialMLLM could become a foundational technology. Its ability to process multi-frame sequences rather than static images represents a significant leap forward.
The research team emphasizes that this is just the beginning. Future work will focus on scaling the model for real-world applications while maintaining computational efficiency.
Key Points
- Meta's Multi-SpatialMLLM overcomes traditional limitations in AI spatial reasoning through multi-frame analysis
- The model integrates three core capabilities: depth perception, visual correspondence, and dynamic scene understanding
- Trained on the expansive MultiSPA dataset containing 27+ million annotated samples
- Demonstrates 36% average improvement over existing models in benchmark tests
- Maintains strong performance on general vision tasks while excelling at specialized spatial reasoning