Meta's New AI Tool Spots Reasoning Flaws Like a Surgeon
Meta's Breakthrough: Making AI Reasoning Transparent
Imagine having an X-ray machine for artificial intelligence - one that could peer inside its "brain" and pinpoint exactly where its reasoning goes wrong. That's essentially what Meta's AI Lab has created with their new CoT-Verifier tool, now available on Hugging Face.
From Black Box to Clear Diagrams
Traditional AI verification stops at checking whether the final answer is correct. Meta's approach digs deeper, analyzing each step in what researchers call the "chain-of-thought" process. 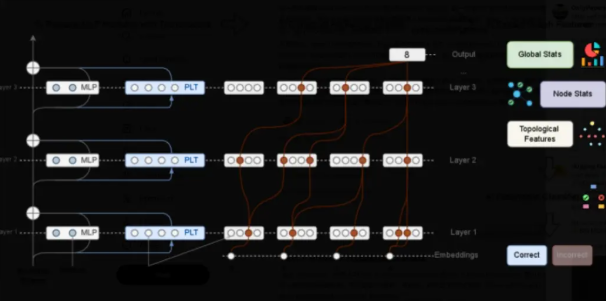
The team discovered something fascinating: correct and incorrect reasoning paths create completely different patterns in the AI's neural networks - as distinct as two separate circuit board designs. By training a simple classifier to recognize these patterns, they've achieved state-of-the-art accuracy in predicting where errors will occur.
"What surprised us most," explains lead researcher Dr. Elena Torres, "is that different types of problems leave unique fingerprints when the AI gets them wrong. Math errors look different from logic mistakes, which in turn differ from common sense failures."
Not Just Diagnosis - Treatment Too
The real magic happens when this diagnostic capability turns therapeutic. Meta's engineers experimented with making targeted adjustments to nodes flagged as high-risk by their system:
- Ablation: Temporarily disabling suspicious nodes
- Weight Shifting: Adjusting how much influence certain connections have
The results? Llama3.1 solved math problems 4.2% more accurately without any full-model retraining required.
How Developers Can Use It Today
The open-source version available on Hugging Face makes adoption simple:
- Feed your chain-of-thought sequence into the Verifier
- Receive structural anomaly scores for each reasoning step
- Identify problematic upstream nodes causing downstream errors
"We're moving from post-mortem analysis to real-time surgical navigation," says Torres enthusiastically about the implications.
What Comes Next?
The paper hints at ambitious next steps:
- Applying similar graph-based interventions to code generation
- Expanding to multimodal reasoning (combining text, images, etc.)
- Establishing "white-box surgery" as standard practice for large language models
As one reviewer noted: "This could fundamentally change how we build trustworthy AI systems."
Key Points:
- Precision Debugging: Identifies exact locations of reasoning flaws
- Task-Specific Patterns: Different error types leave distinctive signatures
- No Retraining Needed: Targeted adjustments boost performance immediately
- Open Access: Available now for developers on Hugging Face