Kimi K2 Matches Top AI Models in Programming Tests
Kimi K2 Programming Model Rivals Industry Leaders
The Aider Leaderboard, an authoritative benchmark for evaluating large language models' code editing capabilities, has released its latest test results. The findings reveal that Kimi K2, an open-source model developed by Moonshot AI, demonstrates programming abilities comparable to top proprietary models while offering significant cost advantages.
Benchmark Performance Breakdown
In comprehensive testing across multilingual programming tasks and complex code editing scenarios, Kimi K2 achieved results rivaling Qwen3-235B-A22B and approaching the performance of o3-mini-high and Claude-3.7-Sonnet. The model's efficient architecture allows it to excel particularly in precise code replacement and multi-step programming tasks.
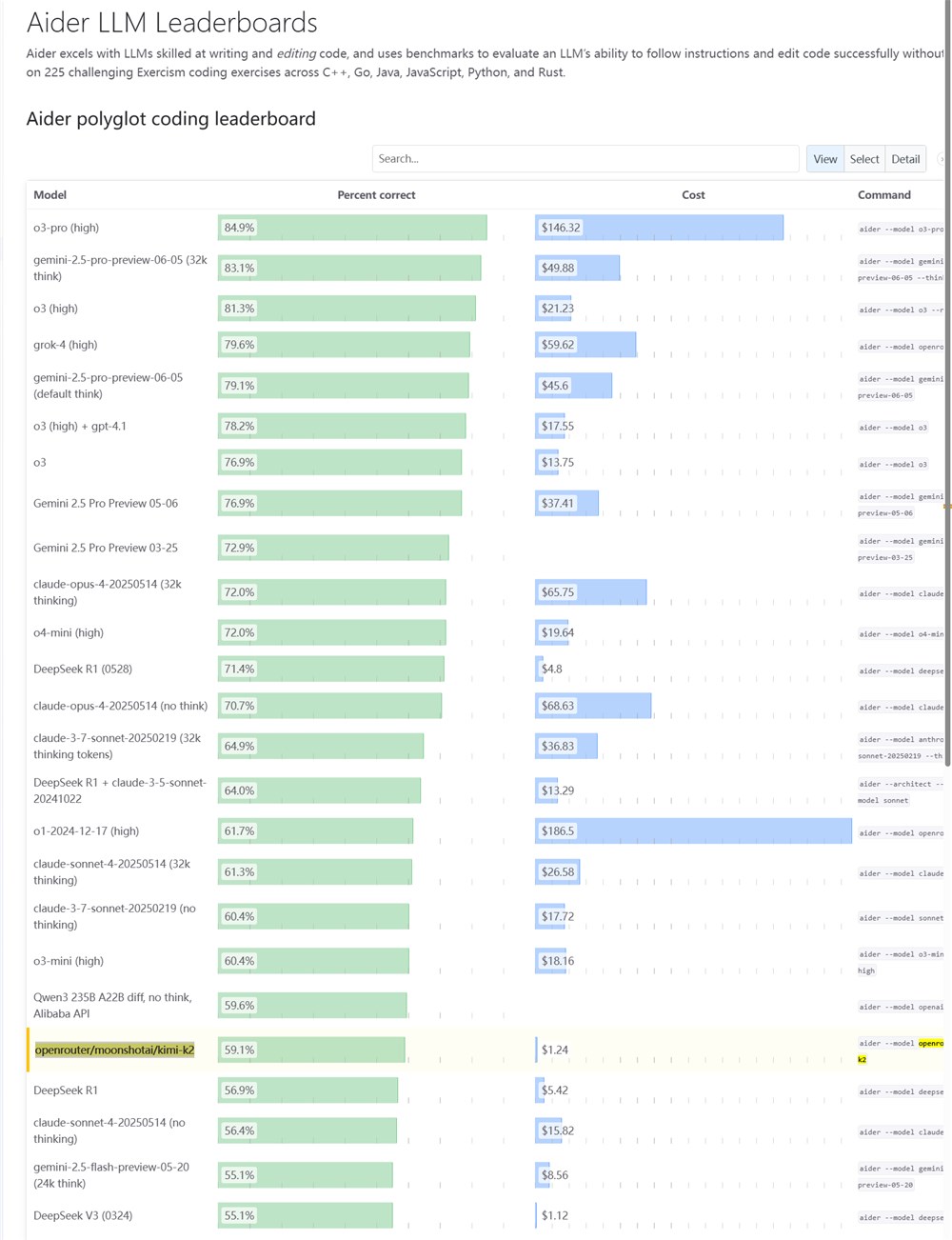
Technical Specifications
- Architecture: Mixture-of-experts (MoE)
- Total Parameters: 1 trillion (32 billion activated per inference)
- Context Length: Supports 128k tokens
Cost-Effective Coding Solution
The model's most compelling advantage lies in its cost-performance ratio. At just $0.14 per million input tokens and $2.49 per million output tokens, Kimi K2's inference costs are approximately one-third of comparable proprietary models like Claude-4-Sonnet.

Performance Metrics:
- SWE-bench Verified: 65.8% accuracy (surpassing GPT-4.1)
- LiveCodeBench: 53.7%
- EvalPlus: 80.3% (leading among open-source models)
Diverse Applications Beyond Coding
Developers report exceptional performance in:
- Web generation tasks (outperforming Claude-4-Sonnet in some cases)
- Automated workflows and code debugging
- Multi-step task processing (e.g., complete video-to-text workflow execution)
The model supports popular inference frameworks including vLLM and Hugging Face, with deployment options through Moonshot AI's API or direct model weight downloads.
Key Points:
- ✅ Open-source alternative with MIT license
- ✅ Superior cost-performance ratio for terminal coding applications
- ✅ Leading scores on multiple programming benchmarks
- ✅ Broad compatibility with existing development ecosystems
- ✅ Strong showing in complex agent-based tasks