IBM and Hugging Face Launch SmolDocling: A Game-Changer in Document Conversion
In the realm of computer science, transforming complex documents into structured data has long been a significant challenge. Traditional methods often involve cumbersome workflows or rely on massive multi-modal models that are prone to errors and high computational costs. However, a new solution has emerged: SmolDocling, a collaborative project by IBM and Hugging Face, promises to revolutionize this space.
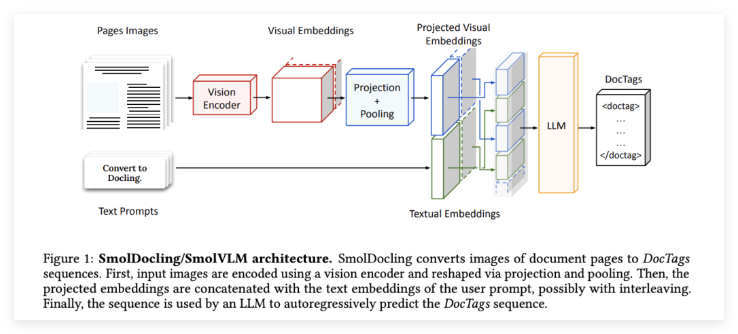
SmolDocling is a 256M parameter open-source vision-language model (VLM) designed to provide an end-to-end solution for multi-modal document conversion. Unlike larger models with billions of parameters, SmolDocling’s compact size makes it a lightweight yet powerful tool, significantly reducing computational complexity and resource requirements.
SmolDocling's Unique Approach
The model’s key innovation lies in its DocTags format, a universal tagging system that captures page elements, their structure, and spatial context in a clear and concise manner. This feature allows for precise machine understanding of document layouts, text content, and visual elements like tables, formulas, code snippets, and charts.
Built on Hugging Face’s SmolVLM-256M, SmolDocling leverages optimized tokenization and aggressive visual feature compression to minimize computational demands. Its training process employs curriculum learning—starting with a frozen visual encoder before progressively fine-tuning it with richer datasets to enhance visual-semantic alignment. Remarkably, SmolDocling processes an average of 0.35 seconds per page on a consumer-grade GPU, consuming less than 500MB of VRAM.
A Lightweight Champion
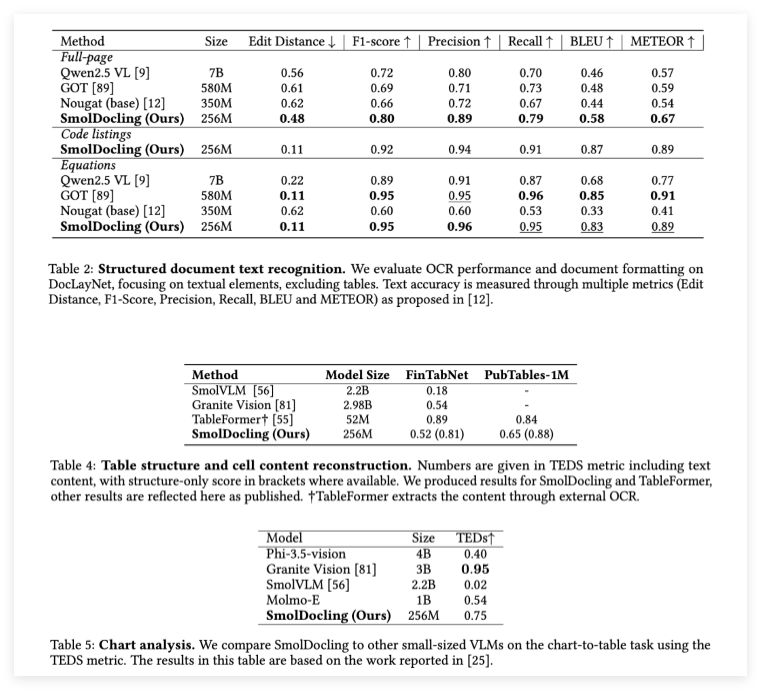
In benchmark tests, SmolDocling has demonstrated exceptional performance. For instance, in full-page document OCR, it outperformed larger models like Qwen2.5VL (7 billion parameters) and Nougat (350 million parameters), achieving a lower edit distance (0.48) and a higher F1 score (0.80). In formula transcription, it matched state-of-the-art models with an F1 score of 0.95. Additionally, it set new standards in code snippet recognition, achieving precision and recall rates of 0.94 and 0.91, respectively.
Versatility in Handling Complex Documents
SmolDocling’s capabilities extend beyond scientific papers to include patents, tables, business documents, and more. Its ability to handle complex elements like code, charts, and diverse layouts sets it apart from traditional OCR solutions. By providing comprehensive structured metadata through DocTags, SmolDocling eliminates ambiguities inherent in formats like HTML or Markdown, enhancing downstream usability.
The model’s compact size also enables large-scale batch processing with minimal resource requirements, offering a cost-effective solution for businesses dealing with massive volumes of complex documents.
Conclusion
SmolDocling represents a significant breakthrough in document conversion technology. It demonstrates that compact models can not only compete with large foundation models but also surpass them in key tasks. Its open-source nature sets a new standard for efficiency and versatility in OCR technology while providing the community with valuable resources through open datasets and an efficient model architecture.
Key Points
- SmolDocling is a 256M parameter open-source vision-language model developed by IBM and Hugging Face.
- It introduces the DocTags format for precise machine understanding of document elements.
- The model processes pages in 0.35 seconds on consumer-grade GPUs with minimal VRAM usage.
- It outperforms larger models in OCR, formula transcription, and code recognition tasks.
- SmolDocling’s versatility makes it suitable for processing patents, business documents, and scientific papers.