Hugging Face Releases SmolLM3: A Compact AI Model Rivaling Larger Counterparts
Hugging Face Introduces SmolLM3: A New Benchmark in Efficient AI
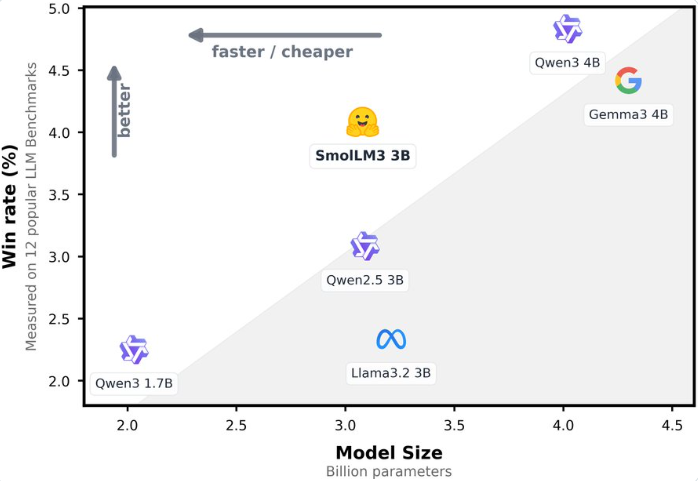
Hugging Face has officially launched SmolLM3, a groundbreaking open-source language model that challenges the conventional wisdom about model size and performance. With just 3 billion parameters, this lightweight large language model (LLM) demonstrates capabilities comparable to larger 4B parameter models like Gemma3, while offering superior efficiency and flexibility.
Performance Beyond Its Size
SmolLM3 represents a significant leap in small-model technology. Built as a decoder-only Transformer model, it incorporates advanced techniques like Grouped Query Attention (GQA) and NoPE to optimize inference efficiency and long-context processing. Pre-trained on an extensive dataset of 11.2 trillion tokens spanning web content, code, mathematics, and reasoning data, SmolLM3 excels in knowledge-intensive tasks.
Benchmark tests reveal remarkable results: SmolLM3 outperforms similar-sized models like Llama-3.2-3B and Qwen2.5-3B, while matching or exceeding the performance of larger 4B models in knowledge and reasoning assessments such as HellaSwag, ARC, and BoolQ.
Innovative Dual-Mode Functionality
One of SmolLM3's most distinctive features is its dual-mode inference system, offering both "thinking" (think) and "non-thinking" (no-think) modes. This innovation allows the model to dynamically adjust its approach based on task complexity:
- In thinking mode, SmolLM3 shows dramatic improvements on challenging benchmarks:
- AIME2025: 36.7% accuracy vs 9.3% in standard mode
- LiveCodeBench: 30.0% vs 15.2%
- GPQA Diamond: 41.7% vs 35.7%
This flexibility enables optimal balance between speed and depth of analysis across different applications.
Extended Context and Multilingual Capabilities
The model sets new standards for small-scale models with its impressive 128K token context window, achieved through YaRN technology expansion from its native 64K training capacity. This makes SmolLM3 particularly effective for processing long documents or maintaining conversation context.
Multilingual support is another strength, with native proficiency in six languages (English, French, Spanish, German, Italian, Portuguese) and additional training in Arabic, Chinese, and Russian. Performance metrics from Global MMLU and Flores-200 tests confirm its position as a leader among similarly sized multilingual models.
Full Open-Source Commitment
True to Hugging Face's philosophy, SmolLM3 launches with complete transparency:
- Publicly available model weights
- Open-sourced training data mix (11.2T tokens)
- Full disclosure of training configurations and code
The company's decision to provide this comprehensive "training blueprint" significantly lowers barriers for academic research and commercial adaptation while fostering innovation within the developer community.
Optimized for Edge Deployment
The model's efficient design makes it particularly suitable for resource-constrained environments:
- Reduced KV cache usage through Grouped Query Attention mechanism
- WebGPU compatibility enables browser-based implementation
- Ideal balance between performance and computational cost creates new possibilities for:
- Educational applications
- Coding assistance tools
- Customer support systems
- Edge device integration
The release represents what Hugging Face describes as finding the "Pareto optimal" point between capability and resource requirements.
Industry Impact and Future Potential
The introduction of SmolLM3 signals a major shift in the AI landscape by proving that smaller models can achieve competitive results when properly optimized. Its combination of performance characteristics makes it particularly attractive for:
- Academic researchers needing transparent models
- Startups requiring cost-effective solutions
- Enterprises implementing localized AI deployments
The full open-source approach may inspire similar transparency across the industry while accelerating innovation through community contributions.
Key Points:
- Compact Powerhouse: At just 3B parameters, SmolLM3 matches or exceeds many 4B models' performance through advanced optimization techniques.
- Flexible Intelligence: Dual-mode inference adapts to task complexity—rapid responses when needed or deeper analysis for challenging problems.
- Extended Context: Industry-leading 128K token capacity enables sophisticated document processing within a small-model framework.
- Global Ready: Robust multilingual support across nine languages positions it well for international deployment scenarios.
- Developer Friendly: Complete open-source release including weights, data mix, training details fosters innovation and customization.