H100 GPU Boosts Flash Attention Performance Without CUDA
H100 GPU Accelerates Flash Attention Without CUDA Code
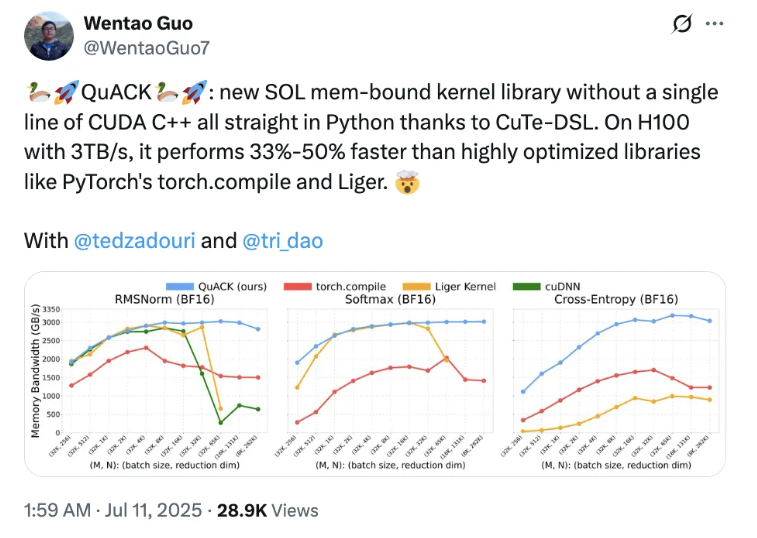
In a breakthrough for GPU optimization, Tri Dao, co-author of Flash Attention, and Princeton researchers have unveiled QuACK, a new kernel library that achieves 33%-50% faster performance on NVIDIA's H100 GPUs without traditional CUDA C++ code. The team used only Python and CuTe-DSL, demonstrating that complex GPU programming can be both accessible and high-performing.
The Python-Powered Performance Leap
The research challenges conventional wisdom about GPU programming by proving that:
- Memory-intensive kernels can be optimized through precise handling of key details
- Modern accelerators' thread and memory hierarchy structures are crucial for performance
- CuTe-DSL, a Python-based domain-specific language, provides a more developer-friendly path to optimization
Industry Experts Weigh In
The achievement has drawn significant attention:
- NVIDIA's CUTLASS team praised the work, noting CuTe-DSL's potential for expert-level GPU optimization
- PyTorch team member Horace He highlighted the innovation's advantages for long sequence processing
- Researchers promise more developments in this space throughout the year
Democratizing GPU Optimization
The QuACK team has published detailed tutorials to help developers:
- Implement memory-intensive kernel optimizations
- Leverage GPU memory hierarchy effectively
- Achieve near "lightning speed" performance without low-level coding
The approach focuses on improving data transfer efficiency rather than compute intensity, making it particularly valuable for memory-bound operations.
Key Points:
- 33%-50% speed boost over torch.compile and Liger on H100 GPUs
- No CUDA C++ required
- uses Python and CuTe-DSL instead
- Focuses on optimizing memory-intensive kernels
- Detailed tutorials available for developer adoption