Google Launches Gemini 2.5 Flash-Lite for AI Efficiency
Google Releases Stable Gemini 2.5 Flash-Lite AI Model
Google has officially announced the general availability (GA) of its Gemini 2.5 Flash-Lite model, positioning it as the fastest and most cost-effective option in its AI lineup. This release marks a significant step in Google's ongoing advancements in artificial intelligence technology.
Performance and Pricing
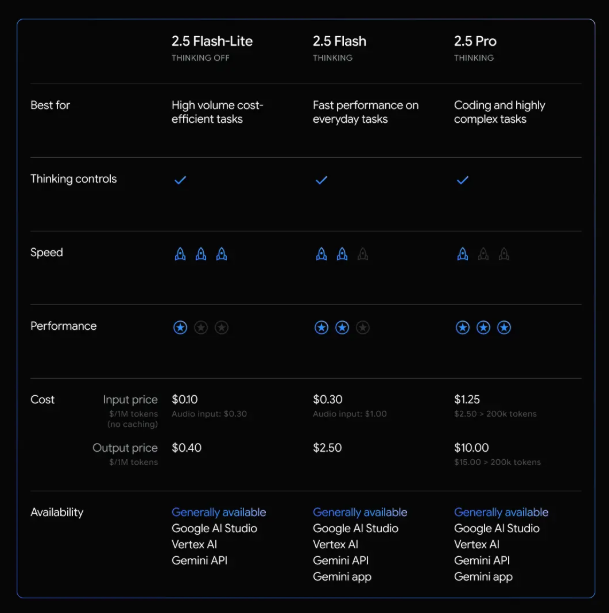
The new model achieves an optimal balance between performance and cost, natively supporting up to 1 million tokens of context. Key pricing details include:
- $0.10 per million input tokens
- $0.40 per million output tokens
These rates are competitive with rival models like GPT-4.1 Nano. Additionally, Google has reduced audio input pricing by 40% compared to the preview version, demonstrating responsiveness to market demands.
Technical Advancements
In benchmark tests, Gemini 2.5 Flash-Lite has shown superior performance to its predecessor (Gemini 2.0) across multiple domains:
- Coding
- Mathematics
- Reasoning
- Multimodal understanding
The model features a 1 million token context window, controllable thinking budgets, and native tools including:
- Google search integration
- Code execution capabilities
- URL context functionality
Developer Implementation
Developers can access the new model by specifying gemini-2.5-flash-lite in their code. Important note: The preview version alias will be discontinued on August 25, urging developers to transition promptly.
Future Outlook
This release underscores Google's commitment to AI innovation, providing developers with more efficient and economical solutions for various applications.
Key Points:
- 🚀 General availability of Gemini 2.5 Flash-Lite
- 💰 Cost-effective pricing: $0.10/$0.40 per million tokens
- ⚙️ Enhanced performance in coding, math, and reasoning
- 📅 Preview version alias removal scheduled for August 25
- 🔍 Native tools including search integration and code execution