Flow-GRPO Revolutionizes AI Image Generation with Reinforcement Learning
A new research breakthrough called Flow-GRPO is transforming how artificial intelligence creates images, solving long-standing challenges in generative models. This innovative approach combines flow-matching techniques with reinforcement learning (RL) to produce remarkably accurate and detailed images.
The Challenge of Complex Image Generation
Current image generation models excel at creating individual objects but struggle with complex scenes requiring precise object placement, attribute control, and text rendering. While reinforcement learning has boosted language models' reasoning abilities, applying it to image generation presented unique hurdles.
"Training RL-based flow models was like trying to merge oil and water," explains the research team. The deterministic nature of flow models clashed with RL's need for random exploration. Additionally, the computational cost of generating samples made online RL training impractical.
How Flow-GRPO Works
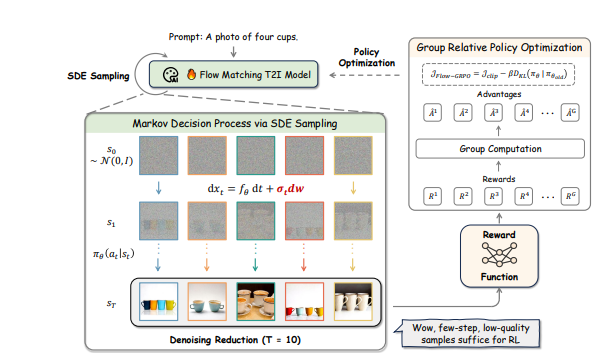
The solution came through two key innovations:
- ODE-to-SDE Conversion: By transforming deterministic ordinary differential equations into stochastic differential equations, the team introduced controlled randomness while preserving output quality.
- Denoising Reduction Strategy: During training, the system uses fewer denoising steps for faster data collection while maintaining full steps during inference for high-quality results.
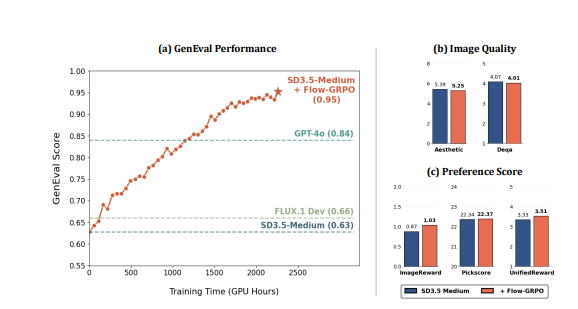
Remarkable Performance Gains
Testing revealed dramatic improvements across multiple benchmarks:
- Compositional image generation accuracy jumped from 63% to 95%
- Text rendering accuracy increased from 59% to 92%
- Human preference alignment improved without sacrificing diversity
The system particularly excels at handling complex prompts involving multiple objects with specific attributes and spatial relationships. Where previous models might misplace items or render text incorrectly, Flow-GRPO maintains precise control.

Future Applications and Challenges
The research team is already exploring applications in video generation, though this presents new obstacles:
- Developing comprehensive reward systems for temporal coherence
- Balancing multiple competing objectives like realism and smoothness
- Addressing the substantial computational requirements
Key Points
- Flow-GRPO combines flow-matching models with reinforcement learning for superior image generation
- The method achieves 95% accuracy in complex compositional tasks - a 32% improvement over baseline models
- Two technical innovations enable efficient RL training without compromising output quality
- Future work will adapt the approach for video generation and other media types