Fei-Fei Li's Team Develops Advanced Multimodal Model
Introduction
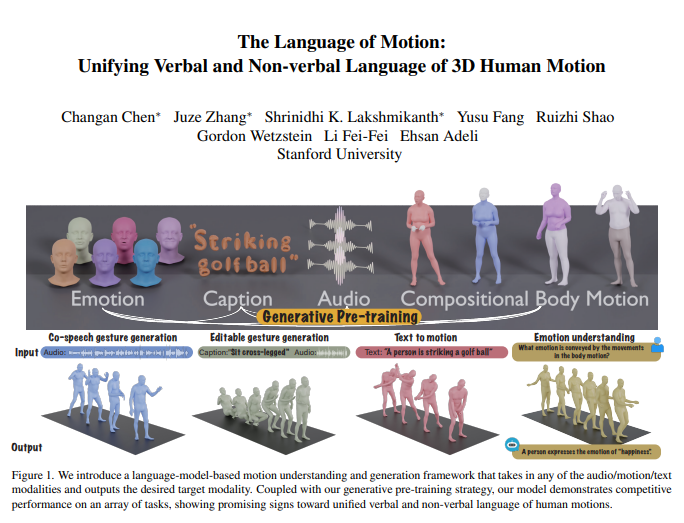
Researchers at Stanford University, led by Fei-Fei Li, have developed a new multimodal model that enhances the understanding of human actions and language. This innovative model not only interprets commands but also reads implicit emotions, significantly improving human-computer interaction.
Model Overview
The core of the model revolves around its multimodal language model framework, which processes diverse inputs including audio, actions, and text. By combining these modalities, the model generates responses that reflect both verbal and non-verbal communication. This integration allows machines to understand human instructions while also interpreting emotional cues conveyed through actions, fostering more intuitive interactions between humans and technology.
Groundbreaking Features
The research demonstrates that the model excels in collaborative speech-gesture generation, outperforming existing technologies while markedly reducing the amount of training data required. This breakthrough opens up new possibilities for applications such as editable gesture generation and emotion prediction through actions.
Human communication is inherently multimodal, comprising verbal elements like speech and non-verbal cues such as facial expressions and body language. The ability of this model to decode these diverse communication forms is vital for developing virtual characters capable of natural interactions in various contexts, including gaming, film, and virtual reality.
Advantages of Integrating Language Models
The researchers identified three primary reasons for utilizing a language model to unify verbal and non-verbal communication:
- Natural Connection: Language models inherently link different modalities.
- Semantic Reasoning: Tasks such as responding to humor require robust semantic understanding, which language models provide.
- Extensive Pre-Training: These models acquire powerful semantic knowledge through extensive training. ### Training Methodology
To implement this model, the team segmented the human body into distinct parts—face, hands, upper body, and lower body—labeling actions for each segment. They created a tokenizer for text and speech, allowing any input modality to be represented as tokens for the language model. The training process consists of two phases:
- Pre-Training: Aligning various modalities with corresponding body actions and audio/text inputs.
- Downstream Tasks: Transforming tasks into instructions for the model to follow various directives. ### Performance and Validation
The model has shown exceptional results in the BEATv2 benchmark for collaborative speech-gesture generation, far exceeding the performance of existing models. Its pre-training strategy proves effective, particularly in scenarios with limited data, showcasing strong generalization capabilities. Post-training on speech-action and text-action tasks enables the model to follow audio and text prompts while introducing functionalities like emotion prediction from action data.
Technical Framework
The model employs modality-specific tokenizers to handle various inputs, training a combined body movement VQ-VAE that converts actions into discrete tokens. This approach merges vocabularies from audio and text into a unified multimodal vocabulary. During training, mixed tokens from different modalities serve as input, with outputs generated through an encoder-decoder language model.
In the pre-training phase, the model learns to perform inter-modal conversion tasks, such as transforming upper body actions into corresponding lower body movements and converting audio into text. It also learns the temporal evolution of actions by randomly masking certain frames.
Key Innovations
In the post-training phase, the model is fine-tuned using paired data for specific tasks like collaborative speech-gesture generation and text-to-action generation. To facilitate natural command following, researchers established a multi-task instruction-following template. This allows the model to interpret tasks like audio-to-action, text-to-action, and emotion-to-action into clear instructions. Additionally, the model can generate coordinated full-body actions based on text and audio prompts.
Emotional Prediction Capabilities
A notable advancement of this model is its ability to predict emotions from actions, an important feature for applications in mental health and psychiatry. Compared to other models, this system demonstrates enhanced accuracy in interpreting emotions expressed through body language.
Conclusion
This research underscores the importance of unifying verbal and non-verbal language in human actions, highlighting that language models are a powerful framework for achieving this goal. Such advancements are crucial for developing practical applications in human-computer interaction, emphasizing the potential for more natural communication with machines.
For further details, access the research paper here.
Key Points
- Fei-Fei Li's team has developed a multimodal model that integrates actions and language.
- The model enhances human-computer interaction by interpreting commands and emotions from actions.
- It significantly outperforms existing models in collaborative speech-gesture generation while requiring less training data.
- New functionalities include editable gesture generation and emotion prediction from actions.
- The model's advancements are pivotal for applications in various fields, including gaming and mental health.